eBPF Offload Native Mode XDP on Intel® Ethernet Linux Driver¶
Intel® ECI enables Linux* eXpress Data Path (XDP) Native Mode (for example, XDP_FLAGS_DRV_MODE) on Intel® Ethernet Linux drivers across multiple industry-graded Ethernet Controllers:
[Ethernet PCI
8086:7aacand8086:7aad] 12th Gen Intel® Core™ S-Series [Alder Lake] Ethernet GbE Time-Sensitive Network Controller[Ethernet PCI
8086:a0ac] 11th Gen Intel® Core™ U-Series and P-Series [Tiger Lake] Ethernet GbE Time-Sensitive Network Controller[Ethernet PCI
8086:4b32and8086:4ba0] Intel® Atom® x6000 Series [Elkhart Lake] Ethernet GbE Time-Sensitive Network Controller[Ethernet PCI
8086:15f2] Intel® Ethernet Controller I225-LM for Time-Sensitive Networking (TSN)[Ethernet PCI
8086:157b,8086:1533,…] Intel® Ethernet Controller I210-T1 for Time-Sensitive Networking (TSN)
Install Linux BPFTool¶
The following section is applicable to:

Install from individual Deb package
make sure ECI Linux intel image packages enabled with eBPF XDP features is
[installed,local]:$ sudo apt search linux-image-intel
For example, a Debian* 11 (Bullseye) distribution set up with ECI Deb packages repository will list the following:
Sorting... Done Full Text Search... Done linux-image-intel/now 5.10.115-bullseye-r0 amd64 [installed,local] intel Linux kernel, version 5.10.115-intel-ese-standard-lts+ linux-image-intel-acrn-sos/now 5.10.115-bullseye-r0 amd64 [installed,local] intel-acrn-sos Linux kernel, version 5.10.115-linux-intel-acrn-sos+ linux-image-intel-acrn-sos-dbg/unknown 5.10.115-bullseye-1 amd64 Linux kernel debugging symbols for 5.10.115-linux-intel-acrn-sos+ linux-image-intel-rt/now 5.10.115-rt67-bullseye-r0 amd64 [installed,local] intel-rt Linux kernel, version 5.10.115-rt67-intel-ese-standard-lts-rt+ linux-image-intel-rt-dbg/unknown 5.10.115-rt67-bullseye-1 amd64 Linux kernel debugging symbols for 5.10.115-rt67-intel-ese-standard-lts-rt+ linux-image-intel-xenomai/now 5.10.100-bullseye-r0 amd64 [installed,local] intel-xenomai Linux kernel, version 5.10.100-intel-ese-standard-lts-dovetail+ linux-image-intel-xenomai-dbg/unknown 5.10.100-bullseye-1 amd64 Linux kernel debugging symbols for 5.10.100-intel-ese-standard-lts-dovetail+
Otherwise, make sure that the running Linux distribution kernel matches the following configuration:
$ zcat /proc/config.gz | grep -e .*BPF.* -e .*XDP.*
CONFIG_CGROUP_BPF=y CONFIG_BPF=y # CONFIG_BPF_LSM is not set CONFIG_BPF_SYSCALL=y CONFIG_ARCH_WANT_DEFAULT_BPF_JIT=y # CONFIG_BPF_JIT_ALWAYS_ON is not set CONFIG_BPF_JIT_DEFAULT_ON=y # CONFIG_BPF_UNPRIV_DEFAULT_OFF is not set # CONFIG_BPF_PRELOAD is not set CONFIG_XDP_SOCKETS=y # CONFIG_XDP_SOCKETS_DIAG is not set CONFIG_IPV6_SEG6_BPF=y # CONFIG_NETFILTER_XT_MATCH_BPF is not set # CONFIG_BPFILTER is not set CONFIG_NET_CLS_BPF=m CONFIG_NET_ACT_BPF=m CONFIG_BPF_JIT=y # CONFIG_BPF_STREAM_PARSER is not set CONFIG_LWTUNNEL_BPF=y CONFIG_HAVE_EBPF_JIT=y CONFIG_BPF_EVENTS=y # CONFIG_BPF_KPROBE_OVERRIDE is not set # CONFIG_TEST_BPF is not set
Install
bpftool-5.1x, provided by ECI, corresponding to the exact Linux Intel tree or from the Linux distribution mainlinebpftool/stable:$ sudo apt search bpftool
For example, an Debian 11 (Bullseye) distribution set up with ECI Deb packages repository will list the following:
Sorting... Done Full Text Search... Done bpftool/stable 5.10.127-1 amd64 Inspection and simple manipulation of BPF programs and maps bpftool-5.10/unknown 5.10.100-bullseye-1 amd64 Inspection and simple manipulation of BPF programs and maps
Note: Intel® ECI ensures that Linux XDP support always matches the Linux Intel LTS branches 2020/lts or 2021/lts (for example, no delta between
kernel/bpfandtools/bpf).The
bpftoolbuilt from Linux Intel 2020/lts tree is recommended for an Debian 11 (Bullseye) installation :$ sudo apt install bpftool-5.10
Also,
bpftoolbuilt from Linux Intel 2021/lts tree is recommended for an Ubuntu* 22.04 (Jammy) installation:$ sudo apt install bpftool-5.15
Linux eXpress Data Path (XDP)¶
The Intel® Linux Ethernet drivers’ Native node XDP offers a standardized Linux API to achieve low-overhead Ethernet Layer2 packet-processing (encoding, decoding, filtering, and so on) on industrial protocols like UADP ETH, ETherCAT, or Profinet-RT/IRT, without any prior knowledge of Intel® Ethernet Controller architecture.
Intel® ECI can leverage the Native mode XDP across Linux eBPF program offload XDP ** and Traffic Control (TC) **BPF Classifier (cls_bpf) in industrial networking usage models.
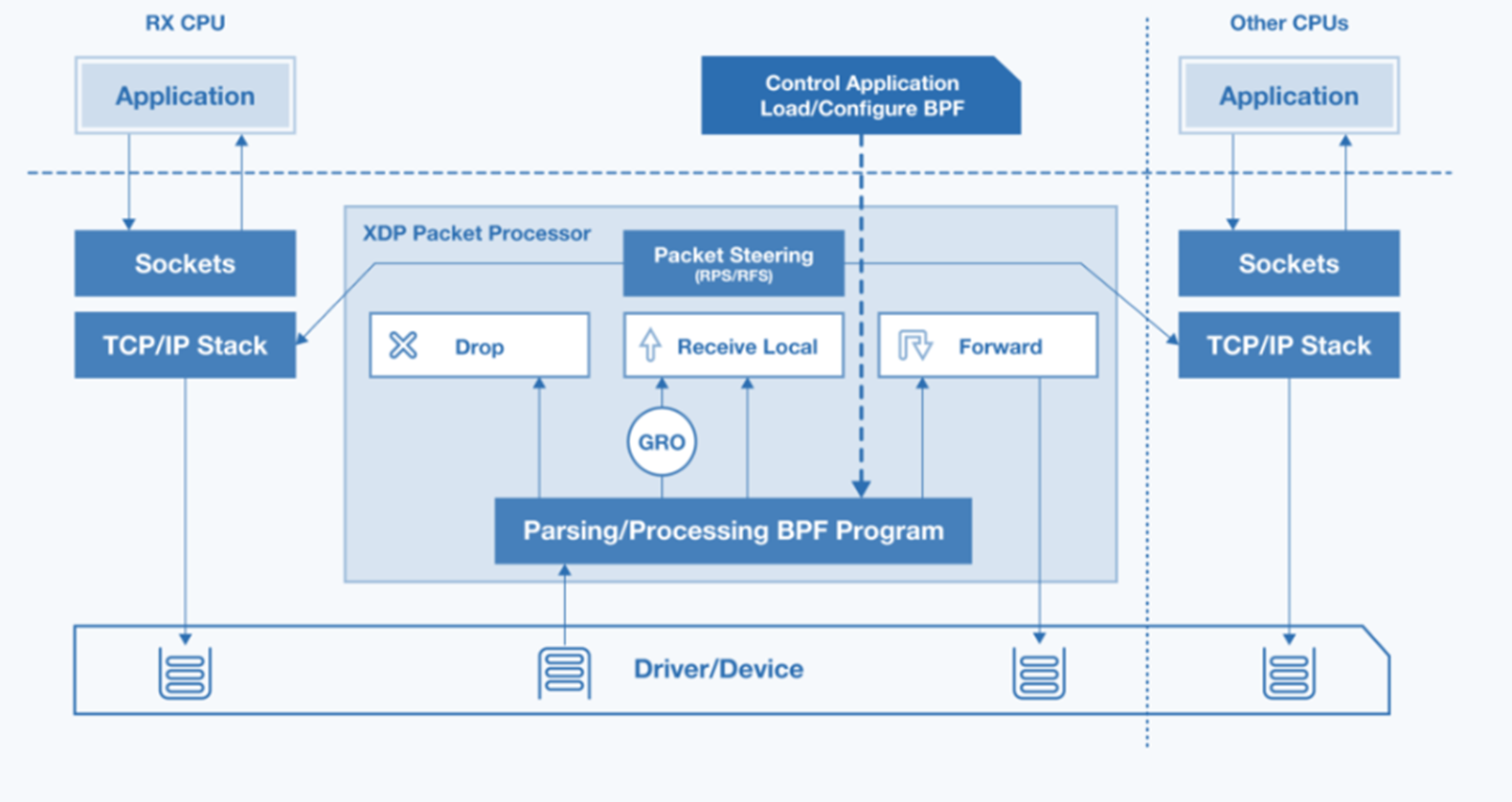
Linux QDisc AF_PACKET socket presents performance limitation. The following table compares both design approaches.
AF_PACKETS Socket with QDisc
AF_XDP Socket/eBPF Offload
Linux Network Stack (TCP/IP, UDP/IP)
Yes
BPF runtime program/library
idg_xdp_ringdirect DMAOSI Layer L4 (Protocol)-L7 (Application)
Yes
No
Number of net packets copied across kernel to users
Several skb_data
memcpyNone in UMEM/Zero-copy mode A few in UMEM/copy mode
IEEE 802.1Q-2018 Enhancements for Scheduled Traffic (EST) Frame Preemption (FPE)
Standardize API for Hardware offload
Customize Hardware offload
Deterministic Ethernet Network Cycle-Time requirement
Moderate
Tight
Per-Packets TxTime constraints
Yes, AF_PACKETS SO_TXTIME cmsg
Yes
AF_XDP(xdp_desc txtime)IEEE 802.1AS L2/PTP RX and TX hardware offload
Yes L2/PTP
Yes L2/PTP
Intel® Ethernet Controllers Linux drivers can handle the most commonly used XDP actions, allowing Ethernet L2-level packets traversing networking stack to be reflected, filtered, or redirected with lowest-latency overhead (for example, DMA accelerated transfer with limited memcpy, XDP_COPY or without any XDP_ZEROCOPY):
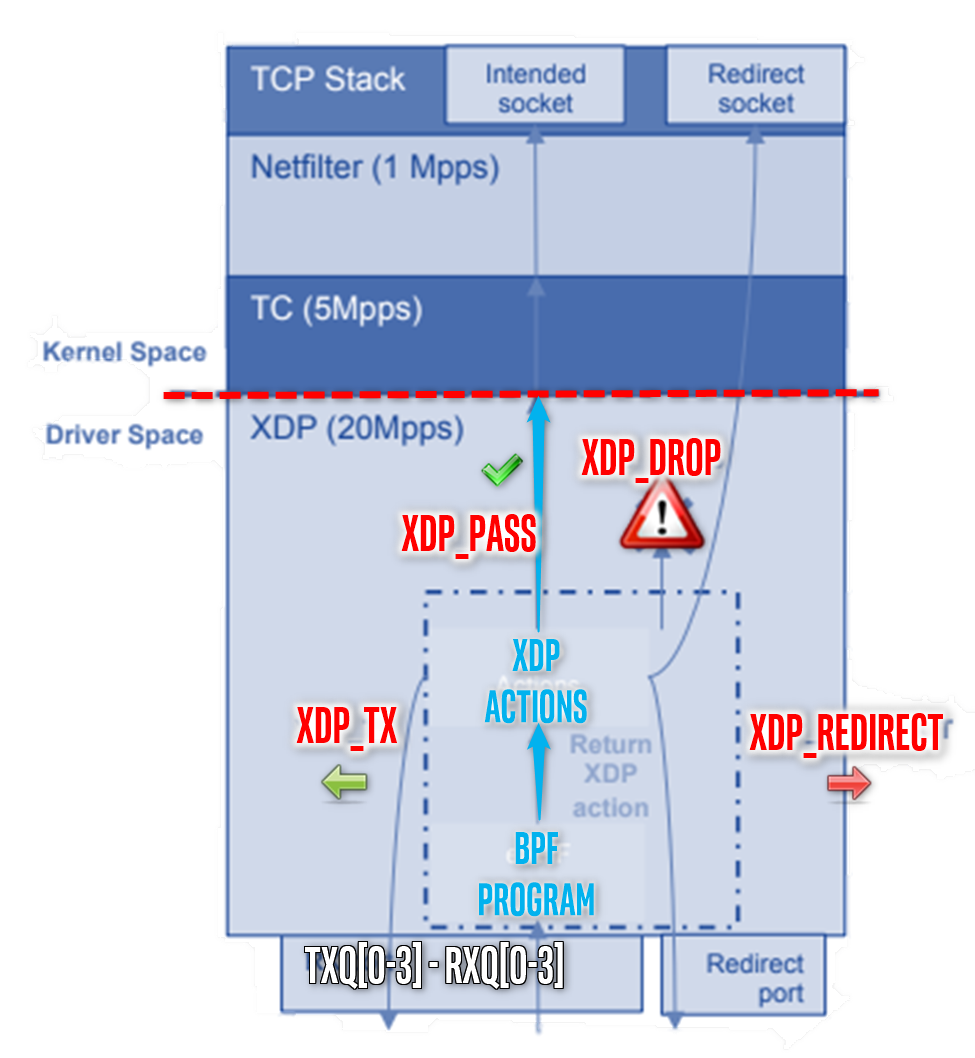
eBPF programs classify/modify traffic and return XDP actions:
XDP_PASS
XDP_DROP
XDP_TX
XDP_REDIRECT
XDP_ABORTNote:
cls_bpfin Linux Traffic Control (TC) works in same manner as the kernel Space.
The following table summarizes the eBPF offload Native mode XDP support available on the Intel® Linux Ethernet controllers.
eBPF Offload
v5.10.y/v5.15.y APIs
Intel® I210/igb.ko
Intel® GbE/stmmac.ko
Intel®I225-LM/igc.ko
XDP program features
XDP_DROPYes
Yes
Yes
XDP_PASSYes
Yes
Yes
XDP_TX8Yes
Yes
Yes
XDP_REDIRECTYes
Yes
Yes
XDP_ABORTEDYes
Yes
Yes
Packet read access
Yes
Yes
Yes
Conditional statements
Yes
Yes
Yes
xdp_adjust_head()Yes
Yes
Yes
bpf_get_prandom_u32()Yes
Yes
Yes
perf_event_output()Yes
Yes
Yes
Partial offload
Yes
Yes
Yes
RSS
rx_queue_indexselectYes
Yes
Yes
bpf_adjust_tail()
Yes
Yes
Yes
XDP maps features
Offload ownership for maps
Yes
Yes
Yes
Hash maps
Yes
Yes
Yes
Array maps
Yes
Yes
Yes
bpf_map_lookup_elem()Yes
Yes
Yes
bpf_map_update_elem()Yes
Yes
Yes
bpf_map_delete_elem()Yes
Yes
Yes
Atomic
sync_fetch_and_adduntested
untested
untested
Map sharing between ports
untested
untested
untested
uarch optimization features
Localized packet cache
untested
untested
untested
32 bit BPF support
untested
untested
untested
Localized maps
untested
untested
untested
xdpdump: A libbpf XDP API Example BPF Program¶
User space programs can interact with the offloaded program in the same way as normal eBPF programs. The kernel will try and offload the program if a non-null ifindex is supplied to the bpf() Linux system call for loading the program.
Maps can be accessed from the kernel using user space eBPF map lookup or update commands.
BPF Helpers include/uapi/linux/bpf.h are used to add functionality that would otherwise be difficult:
Key XDP Map helpers :
bpf_map_lookup_elem
bpf_map_update_elem
bpf_map_delete_elem
bpf_redirect_mapHead Extend:
bpf_xdp_adjust_head
bpf_xdp_adjust_metaOthers
bpf_perf_event_output
bpf_ktime_get_ns
bpf_trace_printk
bpf_tail_call
bpf_redirect
This section provides the steps for creating a very basic IPv4/IPv6 UDP packet-processing eBPF program, leveraging only XDP_PASS and XDP_DROP actions:
Create the eBPF offload XDP
<..._kern>.cthat:Defines
SEC(maps)XDP event ofbpf_map_deftypes such as the user space that can query the object map using the built kernel map lookupbpf_map_lookup_elem()API calls, which are subsequently relayed to theigbdriver. In this example, eBPF program may communicate with the user space using the kernel’sperftracing events.
1struct bpf_map_def SEC("maps") perf_map = { 2 .type = BPF_MAP_TYPE_PERF_EVENT_ARRAY, 3 .key_size = sizeof(__u32), 4 .value_size = sizeof(__u32), 5 .max_entries = MAX_CPU, 6};
Declares all sub-functions as
static __always_inline:1static __always_inline bool parse_udp(void *data, __u64 off, void *data_end, 2 struct pkt_meta *pkt) 3{ 4 struct udphdr *udp; 5 6 udp = data + off; 7 if (udp + 1 > data_end) 8 return false; 9 10 pkt->port16[0] = udp->source; 11 pkt->port16[1] = udp->dest; 12 return true; 13}
Declares the
SEC("xdp")program entry by takingxdp_md *ctxas input and defining the appropriate XDP actions as output - XDP_PASS` in the following example.When ingress packets enter the XDP program, packet metadata is extracted and stored into a data structure. The XDP program sends this metadata, along with the packet contents to the ring buffer denoted in the eBPF
perfevent map using the current CPU index as the key.
1SEC("xdp") 2int process_packet(struct xdp_md *ctx) 3{ 4 void *data_end = (void *)(long)ctx->data_end; 5 void *data = (void *)(long)ctx->data; 6 struct ethhdr *eth = data; 7 struct pkt_meta pkt = {}; 8 __u32 off; 9 10 /* parse packet for IP Addresses and Ports */ 11 off = sizeof(struct ethhdr); 12 if (data + off > data_end) 13 return XDP_PASS; 14 15 pkt.l3_proto = bpf_htons(eth->h_proto); 16 17 if (pkt.l3_proto == ETH_P_IP) { 18 if (!parse_ip4(data, off, data_end, &pkt)) 19 return XDP_PASS; 20 off += sizeof(struct iphdr); 21 } else if (pkt.l3_proto == ETH_P_IPV6) { 22 if (!parse_ip6(data, off, data_end, &pkt)) 23 return XDP_PASS; 24 off += sizeof(struct ipv6hdr); 25 } 26 27 if (data + off > data_end) 28 return XDP_PASS; 29 30 /* obtain port numbers for UDP and TCP traffic */ 31 if (if (pkt.l4_proto == IPPROTO_UDP) { 32 if (!parse_udp(data, off, data_end, &pkt)) 33 return XDP_PASS; 34 off += sizeof(struct udphdr); 35 } else { 36 pkt.port16[0] = 0; 37 pkt.port16[1] = 0; 38 } 39 40 pkt.pkt_len = data_end - data; 41 pkt.data_len = data_end - data - off; 42 43 bpf_perf_event_output(ctx, &perf_map, 44 (__u64)pkt.pkt_len << 32 | BPF_F_CURRENT_CPU, 45 &pkt, sizeof(pkt)); 46 return XDP_PASS; 47}
Compile the XDP program as
x86_64eBPF assembler using the following command on the build system or into Yocto build recipe:$ clang -O2 -S \ -D __BPF_TRACING__ \ -I$(LIBBPF_DIR)/root/usr/include/ \ -Wall \ -Wno-unused-value \ -Wno-pointer-sign \ -Wno-compare-distinct-pointer-types \ -Werror \ -emit-llvm -c -g <..._kern>.c -o <..._kern>.S $ llvm -march=bpf -filetype=obj -o <..._kern>.o <..._kern>.S
Create the
<.._user.c>user spacemain()program that:Initiates
bpf_prog_load_xattr()API call to offload LLV compiled..._kern.oeBPF XDP program, either inXDP_FLAGS_SKB_MODEorXDP_FLAGS_DRV_MODEusingxdp_flagsinput parameter of thebpf_set_link_xdp_fd()API.
1static void usage(const char *prog) 2{ 3 fprintf(stderr, 4 "%s -i interface [OPTS]\n\n" 5 "OPTS:\n" 6 " -h help\n" 7 " -N Native Mode (XDPDRV)\n" 8 " -S SKB Mode (XDPGENERIC)\n" 9 " -x Show packet payload\n", 10 prog); 11} 12 13int main(int argc, char **argv) 14{ 15 static struct perf_event_mmap_page *mem_buf[MAX_CPU]; 16 struct bpf_prog_load_attr prog_load_attr = { 17 .prog_type = BPF_PROG_TYPE_XDP, 18 .file = "xdpdump_kern.o", 19 }; 20 struct bpf_map *perf_map; 21 struct bpf_object *obj; 22 int sys_fds[MAX_CPU]; 23 int perf_map_fd; 24 int prog_fd; 25 int n_cpus; 26 int opt; 27 28 xdp_flags = XDP_FLAGS_DRV_MODE; /* default to DRV */ 29 n_cpus = get_nprocs(); 30 dump_payload = 0; 31 32 if (optind == argc) { 33 usage(basename(argv[0])); 34 return -1; 35 } 36 37 while ((opt = getopt(argc, argv, "hi:NSx")) != -1) { 38 switch (opt) { 39 case 'h': 40 usage(basename(argv[0])); 41 return 0; 42 case 'i': 43 ifindex = if_nametoindex(optarg); 44 break; 45 case 'N': 46 xdp_flags = XDP_FLAGS_DRV_MODE; 47 break; 48 case 'S': 49 xdp_flags = XDP_FLAGS_SKB_MODE; 50 break; 51 case 'x': 52 dump_payload = 1; 53 break; 54 default: 55 printf("incorrect usage\n"); 56 usage(basename(argv[0])); 57 return -1; 58 } 59 } 60 61 if (ifindex == 0) { 62 printf("error, invalid interface\n"); 63 return -1; 64 } 65 66 /* use libbpf to load program */ 67 if (bpf_prog_load_xattr(&prog_load_attr, &obj, &prog_fd)) { 68 printf("error with loading file\n"); 69 return -1; 70 } 71 72 if (prog_fd < 1) { 73 printf("error creating prog_fd\n"); 74 return -1; 75 } 76 77 signal(SIGINT, unload_prog); 78 signal(SIGTERM, unload_prog); 79 80 /* use libbpf to link program to interface with corresponding flags */ 81 if (bpf_set_link_xdp_fd(ifindex, prog_fd, xdp_flags) < 0) { 82 printf("error setting fd onto xdp\n"); 83 return -1; 84 } 85 86 perf_map = bpf_object__find_map_by_name(obj, "perf_map"); 87 perf_map_fd = bpf_map__fd(perf_map); 88 89 if (perf_map_fd < 0) { 90 printf("error cannot find map\n"); 91 return -1; 92 } 93 94 /* Initialize perf rings */ 95 if (setup_perf_poller(perf_map_fd, sys_fds, n_cpus, &mem_buf[0])) 96 return -1; 97 98 event_poller(mem_buf, sys_fds, n_cpus); 99 100 return 0; 101}
perf events map
perf_map_fdfile handle is registered viabpf_map_update_elem()method call, so it can be retrieved using thebpf_object__find_map_by_name()API:
1 int setup_perf_poller(int perf_map_fd, int *sys_fds, int cpu_total, 2 struct perf_event_mmap_page **mem_buf) 3 { 4 struct perf_event_attr attr = { 5 .sample_type = PERF_SAMPLE_RAW | PERF_SAMPLE_TIME, 6 .type = PERF_TYPE_SOFTWARE, 7 .config = PERF_COUNT_SW_BPF_OUTPUT, 8 .wakeup_events = 1, 9 }; 10 int mmap_size; 11 int pmu; 12 int n; 13 14 mmap_size = getpagesize() * (PAGE_CNT + 1); 15 16 for (n = 0; n < cpu_total; n++) { 17 /* create perf fd for each thread */ 18 pmu = sys_perf_event_open(&attr, -1, n, -1, 0); 19 if (pmu < 0) { 20 printf("error setting up perf fd\n"); 21 return 1; 22 } 23 /* enable PERF events on the fd */ 24 ioctl(pmu, PERF_EVENT_IOC_ENABLE, 0); 25 26 /* give fd a memory buf to write to */ 27 mem_buf[n] = mmap(NULL, mmap_size, PROT_READ | PROT_WRITE, 28 MAP_SHARED, pmu, 0); 29 if (mem_buf[n] == MAP_FAILED) { 30 printf("error creating mmap\n"); 31 return 1; 32 } 33 /* point eBPF map entries to fd */ 34 assert(!bpf_map_update_elem(perf_map_fd, &n, &pmu, BPF_ANY)); 35 sys_fds[n] = pmu; 36 } 37 return 0; 38 }
Defines the
event_poller()loop for polling theperf_event_headerevents rings and epochtimestampis done by registering with the`bpf_perf_event_read_simple()API the ringevent_received()andevent_print()call to the XDP program.
1 struct pkt_meta { 2 union { 3 __be32 src; 4 __be32 srcv6[4]; 5 }; 6 union { 7 __be32 dst; 8 __be32 dstv6[4]; 9 }; 10 __u16 port16[2]; 11 __u16 l3_proto; 12 __u16 l4_proto; 13 __u16 data_len; 14 __u16 pkt_len; 15 __u32 seq; 16 }; 17 18 struct perf_event_sample { 19 struct perf_event_header header; 20 __u64 timestamp; 21 __u32 size; 22 struct pkt_meta meta; 23 __u8 pkt_data[64]; 24 }; 25 26 static enum bpf_perf_event_ret event_received(void *event, void *printfn) 27 { 28 int (*print_fn)(struct perf_event_sample *) = printfn; 29 struct perf_event_sample *sample = event; 30 31 if (sample->header.type == PERF_RECORD_SAMPLE) 32 return print_fn(sample); 33 else 34 return LIBBPF_PERF_EVENT_CONT; 35 } 36 37 int event_poller(struct perf_event_mmap_page **mem_buf, int *sys_fds, 38 int cpu_total) 39 { 40 struct pollfd poll_fds[MAX_CPU]; 41 void *buf = NULL; 42 size_t len = 0; 43 int total_size; 44 int pagesize; 45 int res; 46 int n; 47 48 /* Create pollfd struct to contain poller info */ 49 for (n = 0; n < cpu_total; n++) { 50 poll_fds[n].fd = sys_fds[n]; 51 poll_fds[n].events = POLLIN; 52 } 53 54 pagesize = getpagesize(); 55 total_size = PAGE_CNT * pagesize; 56 for (;;) { 57 /* Poll fds for events, 250ms timeout */ 58 poll(poll_fds, cpu_total, 250); 59 60 for (n = 0; n < cpu_total; n++) { 61 if (poll_fds[n].revents) { /* events found */ 62 res = bpf_perf_event_read_simple(mem_buf[n], 63 total_size, 64 pagesize, 65 &buf, &len, 66 event_received, 67 event_printer); 68 if (res != LIBBPF_PERF_EVENT_CONT) 69 break; 70 } 71 } 72 } 73 free(buf); 74 }
In this example, when an event is received, the
event_received()callback prints out theperfevent’s metadatapkt_metaand epochtimestampto the terminal. You can also specify if the packet contentspkt_datashould be dumped in hexadecimal format.1void meta_print(struct pkt_meta meta, __u64 timestamp) 2{ 3 char src_str[INET6_ADDRSTRLEN]; 4 char dst_str[INET6_ADDRSTRLEN]; 5 char l3_str[32]; 6 char l4_str[32]; 7 8 switch (meta.l3_proto) { 9 case ETH_P_IP: 10 strcpy(l3_str, "IP"); 11 inet_ntop(AF_INET, &meta.src, src_str, INET_ADDRSTRLEN); 12 inet_ntop(AF_INET, &meta.dst, dst_str, INET_ADDRSTRLEN); 13 break; 14 case ETH_P_IPV6: 15 strcpy(l3_str, "IP6"); 16 inet_ntop(AF_INET6, &meta.srcv6, src_str, INET6_ADDRSTRLEN); 17 inet_ntop(AF_INET6, &meta.dstv6, dst_str, INET6_ADDRSTRLEN); 18 break; 19 case ETH_P_ARP: 20 strcpy(l3_str, "ARP"); 21 break; 22 default: 23 sprintf(l3_str, "%04x", meta.l3_proto); 24 } 25 26 switch (meta.l4_proto) { 27 case IPPROTO_TCP: 28 sprintf(l4_str, "TCP seq %d", ntohl(meta.seq)); 29 break; 30 case IPPROTO_UDP: 31 strcpy(l4_str, "UDP"); 32 break; 33 case IPPROTO_ICMP: 34 strcpy(l4_str, "ICMP"); 35 break; 36 default: 37 strcpy(l4_str, ""); 38 } 39 40 printf("%lld.%06lld %s %s:%d > %s:%d %s, length %d\n", 41 timestamp / NS_IN_SEC, (timestamp % NS_IN_SEC) / 1000, 42 l3_str, 43 src_str, ntohs(meta.port16[0]), 44 dst_str, ntohs(meta.port16[1]), 45 l4_str, meta.data_len); 46} 47 48int event_printer(struct perf_event_sample *sample) 49{ 50 int i; 51 52 meta_print(sample->meta, sample->timestamp); 53 54 if (dump_payload) { /* print payload hex */ 55 printf("\t"); 56 for (i = 0; i < sample->meta.pkt_len; i++) { 57 printf("%02x", sample->pkt_data[i]); 58 59 if ((i + 1) % 16 == 0) 60 printf("\n\t"); 61 else if ((i + 1) % 2 == 0) 62 printf(" "); 63 } 64 printf("\n"); 65 } 66 return LIBBPF_PERF_EVENT_CONT; 67}
Compile and link the program to
libbpfandlibelfusing the GCC commandgcc -lbpf -lelf -I$(LIBBPF_DIR)/root/usr/include/ -I../headers/ -L$(LIBBPF_DIR) -c <.._user>.c -o <.._user>.
** RX Receive Side Scaling (RSS) Queue**
The Intel® Ethernet Controller Linux drivers (igb.ko and igc.ko and stmmac-pci.ko) allow the eBPF program to leverage via XDP the Receive Side Scaling (RSS) queue feature to optimized ingress traffic load.
In the following example, all received packets will be placed onto queue 1:
SEC("xdp") int process_packet(struct xdp_md *ctx) { ctx->rx_queue_index = 1; ... return XDP_PASS; }
AF_XDP Socket (CONFIG_XDP_SOCKETS)¶
An AF_XDP socket (XSK) is created with the normal socket() system call. Two rings are associated with each XSK: the RX ring and the TX ring. A socket can receive packets on the RX ring and it can send packets on the TX ring. These rings are registered and sized with the setsockopts - XDP_RX_RING and XDP_TX_RING, respectively. It is mandatory to have at least one of these rings for each socket. An RX or TX descriptor ring points to a data buffer in a memory area called a UMEM. RX and TX can share the same UMEM so that a packet does not have to be copied between RX and TX. Moreover, if a packet needs to be kept for a while due to a possible retransmit, the descriptor that points to that packet can be changed to point to another and reused right away. This avoids copying of data.
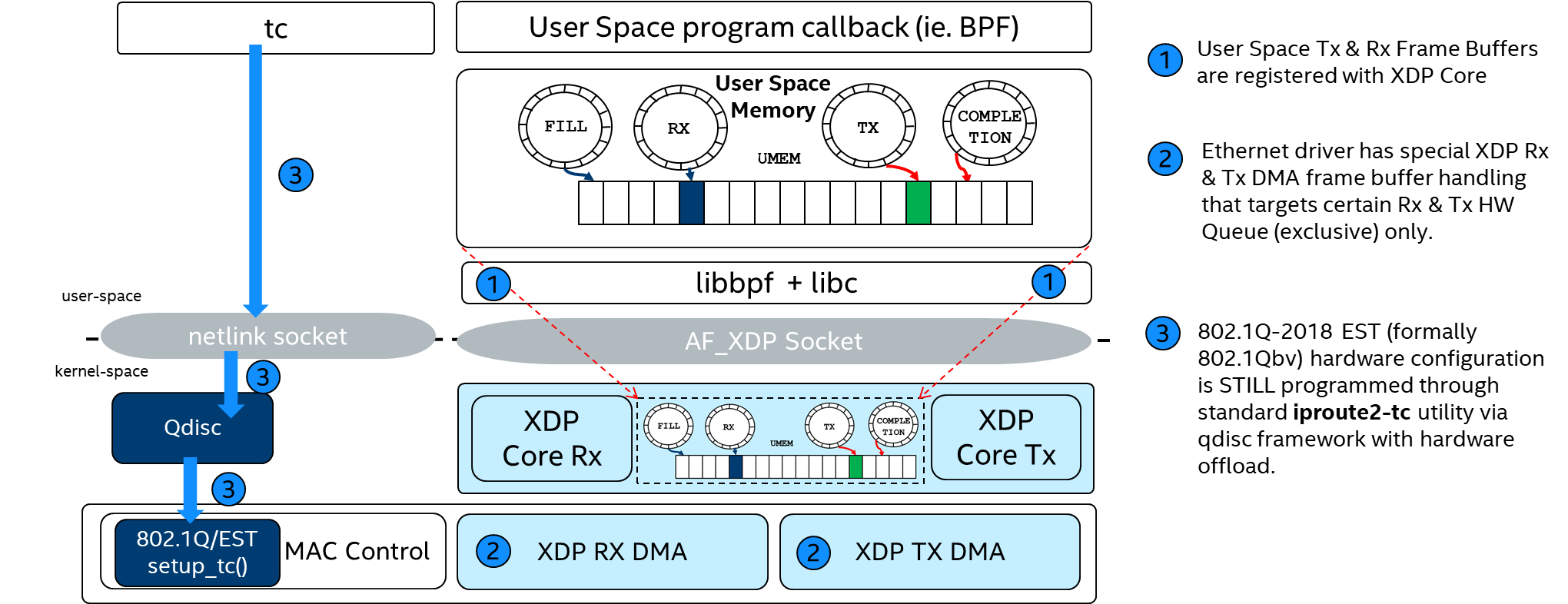
Kernel feature CONFIG_XDP_SOCKETS allows the Linux drivers igb.ko, igc.ko, and stmmac-pci.ko to offload to the eBPF program XDP for transferring the packets up to the user space using AF_XDP.
You can install all officially supported Linux BPF samples eBPF sample programs as Debian packages from the ECI APT repository.
The following section is applicable to:
Setup the ECI APT repository, then perform either of the following commands to install this component:
- Install from meta-package
$ sudo apt install eci-realtime-benchmarking
Install from individual Deb package
For example, on Debian 11 (Bullseye), run the following command to install the
linux-bpf-samplespackage from Linux Intel 2020/lts tree.$ sudo apt install linux-bpf-samples bpftool-5.10Alternatively on Ubuntu 22.04 (Jammy), run the following command to install the
linux-bpf-samplespackage from Linux Intel 2021/lts tree.$ sudo apt install linux-bpf-samples bpftool-5.15Note: From Linux v5.15 onward, the
vmlinux.hgenerated header (CONFIG_DEBUG_INFO_BTF=y) is recommended for the BPF program to improve portability whenlibbpfenables Compile once, run everywhere (CO:RE)”. It contains all type definitions that Linux Intel 2021/lts running Linux kernel uses in its own source code.$ bpftool btf dump file /sys/kernel/btf/vmlinux format c > /tmp/vmlinux.h
Usage
The Linux BPF sample program xdpsock provides a stable reference to understand and experiment with the AF_XDP socket API.
$ xdpsock -hUsage: xdpsock [OPTIONS] Options: -r, --rxdrop Discard all incoming packets (default) -t, --txonly Only send packets -l, --l2fwd MAC swap L2 forwarding -i, --interface=n Run on interface n -q, --queue=n Use queue n (default 0) -p, --poll Use poll syscall -S, --xdp-skb=n Use XDP skb-mod -N, --xdp-native=n Enforce XDP native mode -n, --interval=n Specify statistics update interval (default 1 sec). -z, --zero-copy Force zero-copy mode. -c, --copy Force copy mode. -m, --no-need-wakeup Turn off use of driver need wakeup flag. -f, --frame-size=n Set the frame size (must be a power of two in aligned mode, default is 4096). -u, --unaligned Enable unaligned chunk placement -M, --shared-umem Enable XDP_SHARED_UMEM -F, --force Force loading the XDP prog -d, --duration=n Duration in secs to run command. Default: forever. -b, --batch-size=n Batch size for sending or receiving packets. Default: 64 -C, --tx-pkt-count=n Number of packets to send. Default: Continuous packets. -s, --tx-pkt-size=n Transmit packet size. (Default: 64 bytes) Min size: 64, Max size 4096. -P, --tx-pkt-pattern=nPacket fill pattern. Default: 0x12345678 -x, --extra-stats Display extra statistics. -Q, --quiet Do not display any stats. -a, --app-stats Display application (syscall) statistics. -I, --irq-string Display driver interrupt statistics for interface associated with irq-string.
In the following example, the ingress traffic of the eth3 Ethernet device queue 1 using Intel® Ethernet Controller driver Native mode supports mostly the XDP_RX action.
$ xdpsock -i eth3 -q 1 -Nsock0@eth3:1 rxdrop xdp-drv pps pkts 1.01 rx 0 0 tx 0 0 sock0@eth3:1 rxdrop xdp-drv pps pkts 1.00 rx 0 0 tx 0 0
Display the active eBPF xdp_sock_prog program exposing the AF_XDP socket:
bpftool prog show17: cgroup_skb tag 6deef7357e7b4530 gpl loaded_at 2019-10-25T06:12:41+0000 uid 0 xlated 64B not jited memlock 4096B 18: cgroup_skb tag 6deef7357e7b4530 gpl loaded_at 2019-10-25T06:12:41+0000 uid 0 xlated 64B not jited memlock 4096B 19: cgroup_skb tag 6deef7357e7b4530 gpl loaded_at 2019-10-25T06:12:41+0000 uid 0 xlated 64B not jited memlock 4096B 20: cgroup_skb tag 6deef7357e7b4530 gpl loaded_at 2019-10-25T06:12:41+0000 uid 0 xlated 64B not jited memlock 4096B 21: cgroup_skb tag 6deef7357e7b4530 gpl loaded_at 2019-10-25T06:12:41+0000 uid 0 xlated 64B not jited memlock 4096B 22: cgroup_skb tag 6deef7357e7b4530 gpl loaded_at 2019-10-25T06:12:41+0000 uid 0 xlated 64B not jited memlock 4096B 83: xdp name xdp_sock_prog tag c85daa2f1b3c395f gpl loaded_at 2019-10-28T00:00:38+0000 uid 0 xlated 176B not jited memlock 4096B map_ids 45,46
Display the active xsk_map kernel memory space allocated by the eBPF program:
$ bpftool map show45: array name qidconf_map flags 0x0 key 4B value 4B max_entries 1 memlock 4096B 46: xskmap name xsks_map flags 0x0 key 4B value 4B max_entries 4 memlock 4096B 47: percpu_array name rr_map flags 0x0 key 4B value 4B max_entries 1 memlock 4096B
BPF Compiler Collection (BCC)¶
BPF Compiler Collection (BCC) makes it easy to build and load BPF programs into the kernel directly from Python code. This can be used for XDP packet processing. For more details, refer to the BCC web site.
By using BCC from a container in ECI, you can develop and test BPF programs attached to TSN NICs directly on the target without the need for a separate build system.
The following BCC XDP Redirect example is derived from the kernel self test. It creates two namespaces with two veth peers, and forwards packets in-between using generic XDP.
The following section is applicable to:
Create the
vethdevices and their peers in their respective namespaces:$ ip netns add ns1 $ ip netns add ns2 $ ip link add veth1 index 111 type veth peer name veth11 netns ns1 $ ip link add veth2 index 222 type veth peer name veth22 netns ns2 $ ip link set veth1 up $ ip link set veth2 up $ ip -n ns1 link set dev veth11 up $ ip -n ns2 link set dev veth22 up $ ip -n ns1 addr add 10.1.1.11/24 dev veth11 $ ip -n ns2 addr add 10.1.1.22/24 dev veth22
Make sure that pinging from the
vethpeer in one namespace to the othervethpeer in another namespace does not work in any direction without XDP redirect:$ ip netns exec ns1 ping -c 1 10.1.1.22 PING 10.1.1.22 (10.1.1.22): 56 data bytes --- 10.1.1.22 ping statistics --- 1 packets transmitted, 0 packets received, 100% packet loss
$ ip netns exec ns2 ping -c 1 10.1.1.11 PING 10.1.1.11 (10.1.1.11): 56 data bytes --- 10.1.1.11 ping statistics --- 1 packets transmitted, 0 packets received, 100% packet loss
In another terminal, run the BCC container:
$ docker run -it --rm \ --name bcc \ --privileged \ --net=host \ -v /lib/modules/$(uname -r)/build:/lib/modules/host-build:ro \ bcc
Inside the container, create a new file
xdp_redirect.pywith the following content:#!/usr/bin/python from bcc import BPF import time import sys b = BPF(text = """ #include <uapi/linux/bpf.h> int xdp_redirect_to_111(struct xdp_md *xdp) { return bpf_redirect(111, 0); } int xdp_redirect_to_222(struct xdp_md *xdp) { return bpf_redirect(222, 0); } """, cflags=["-w"]) flags = (1 << 1) # XDP_FLAGS_SKB_MODE #flags = (1 << 2) # XDP_FLAGS_DRV_MODE b.attach_xdp("veth1", b.load_func("xdp_redirect_to_222", BPF.XDP), flags) b.attach_xdp("veth2", b.load_func("xdp_redirect_to_111", BPF.XDP), flags) print("BPF programs loaded and redirecting packets, hit CTRL+C to stop") while 1: try: time.sleep(1) except KeyboardInterrupt: print("Removing BPF programs") break; b.remove_xdp("veth1", flags) b.remove_xdp("veth2", flags)
Run
xdp_redirect.pyto load eBPF program :$ python3 xdp_redirect.py BPF programs loaded and redirecting packets, hit CTRL+C to stop
In the first terminal, make sure that pinging from the
vethpeer in one namespace$ ip netns exec ns1 ping -c 1 10.1.1.22
PING 10.1.1.22 (10.1.1.22): 56 data bytes 64 bytes from 10.1.1.22: seq=0 ttl=64 time=0.067 ms --- 10.1.1.22 ping statistics --- 1 packets transmitted, 1 packets received, 0% packet loss round-trip min/avg/max = 0.067/0.067/0.067 ms
In the second terminal,
vethpeer in another namespace works in both directions due to XDP redirect:$ ip netns exec ns2 ping -c 1 10.1.1.11
PING 10.1.1.11 (10.1.1.11): 56 data bytes 64 bytes from 10.1.1.11: seq=0 ttl=64 time=0.044 ms --- 10.1.1.11 ping statistics --- 1 packets transmitted, 1 packets received, 0% packet loss round-trip min/avg/max = 0.044/0.044/0.044 ms
XDP Sanity Check¶
Sanity Check #1: Load and Execute eBPF Offload Program with “Generic mode” XDP¶
Install both xdpdump example pre-built and iPerf - The ultimate speed test tool for TCP, UDP and SCTP:
$ sudo apt install xdpdump iperf3
Generate UDP traffic between talker and listener:
Set a L4-level UDP Listener on Ethernet device
enp1s0with IPv4, for example set to 192.168.1.206:$ ip addr add 192.168.1.206/24 brd 192.168.0.255 dev enp1s0 $ iperf3 -s
----------------------------------------------------------- Server listening on 5201 -----------------------------------------------------------
Set a L4-level UDP Talker with 1448 bytes payload size on another node Ethernet device
enp1s0with a different IPv4 address, for example set to 192.168.1.203:$ ip addr add 192.168.1.203/24 brd 192.168.0.255 dev enp1s0 $ iperf3 -c 192.168.1.206 -t 600 -b 0 -u -l 1448
Connecting to host 192.168.1.206, port 5201 [ 5] local 192.168.1.203 port 36974 connected to 192.168.1.206 port 5201 [ ID] Interval Transfer Bitrate Total Datagrams [ 5] 0.00-1.00 sec 114 MBytes 957 Mbits/sec 82590 [ 5] 1.00-2.00 sec 114 MBytes 956 Mbits/sec 82540
Execute the precompiled BPF XDP program loaded on the device in “Generic mode” XDP (for example,
XDP_FLAGS_SKB_MODE) with successfulXDP_PASSandXDP_DROPactions:$ cd /opt/xdp/bpf-samples $ ./xdpdump -i enp1s0 -S
73717.493449 IP 192.168.1.203:36974 > 192.168.1.206:5201 UDP, length 1448 73717.493453 IP 192.168.1.203:36974 > 192.168.1.206:5201 UDP, length 1448 73717.493455 IP 192.168.1.203:36974 > 192.168.1.206:5201 UDP, length 1448 73717.493458 IP 192.168.1.203:36974 > 192.168.1.206:5201 UDP, length 1448
Check whether the active eBPF program has loaded the Linux interface
enp1s0“Generic mode” XDP (xdpgeneric) on Intel® Ethernet Controller:$ ip link show dev enp1s0
3: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 xdpgeneric qdisc mq state UP mode DEFAULT group default qlen 1000 link/ether 9c:69:b4:61:82:73 brd ff:ff:ff:ff:ff:ff prog/xdp id 18 tag a5fe55ab7ae19273
Press Ctrl + C to unload the XDP program:
^Cunloading xdp program...
Sanity Check #2: Load and Execute eBPF Offload program with “Native mode” XDP¶
Generate UDP traffic between talker and listener similar to sanity check #1.
Execute the precompiled BPF XDP program loaded on the device in “Native mode” XDP with successful
XDP_PASSandXDP_DROPactions:$ cd /opt/xdp/bpf-samples $ ./xdpdump -i enp1s0 -N
673485.966036 0026 :0 > :0 , length 46 673486.626951 88cc :0 > :0 , length 236 673486.646948 TIMESYNC :0 > :0 , length 52 673487.646943 TIMESYNC :0 > :0 , length 52 ... 673519.134258 IP 192.168.1.1:67 > 192.168.1.206:68 UDP, length 300 673519.136024 IP 192.168.1.1:67 > 192.168.1.206:68 UDP, length 300 673519.649768 TIMESYNC 192.168.1.1:0 > 192.168.1.206:0 , length 52
Check whether the active eBPF program has loaded the Linux interface
enp1s0in “Native mode” XDP (XDP_FLAGS_DRV_MODE) on Intel® Ethernet Controller:$ ip link show dev enp1s0
3: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 xdp qdisc mq state UP mode DEFAULT group default qlen 1000 link/ether 9c:69:b4:61:82:73 brd ff:ff:ff:ff:ff:ff prog/xdp id 80 tag a5fe55ab7ae19273
Press Ctrl + C to the unload XDP program:
^Cunloading xdp program...
Sanity Check #3: Load and Execute “Native mode” AF_XDP Socket Default XDP_COPY¶
Set up two or more ECI nodes according to the AF_XDP Socket (CONFIG_XDP_SOCKETS) guidelines.
Execute a
XDP_RXaction from the precompiled BPF XDP program loaded usingigc.koorigb.koandstmmac.koIntel® Ethernet Controller Linux interface under Native mode with default XDP_COPY:xdpsock -i enp0s30f4 -q 0 -N -c
sock0@enp0s30f4:0 rxdrop xdp-drv pps pkts 1.01 rx 0 0 tx 0 0 sock0@enp0s30f4:0 rxdrop xdp-drv pps pkts 1.00 rx 0 0 tx 0 0 sock0@enp0s30f4:0 rxdrop xdp-drv pps pkts 1.00 rx 0 0 tx 0 0 sock0@enp0s30f4:0 rxdrop xdp-drv pps pkts 1.00 rx 0 0 tx 0 0 ^C sock0@enp0s30f4:0 rxdrop xdp-drv pps pkts 0.47 rx 0 0 tx 0 0
Display the Ethernet interface active eBPF program in “Native mode” with
XDP_COPY:$ ip link show dev enp0s30f4
3: enp0s30f4: <BROADCAST,MULTICAST,DYNAMIC,UP,LOWER_UP> mtu 1500 xdp qdisc mq state UP mode DEFAULT group default qlen 1000 link/ether 88:ab:cd:11:01:23 brd ff:ff:ff:ff:ff:ff prog/xdp id 29 tag 992d9ddc835e5629
Display the eBPF program actively exposing the
AF_XDPsocket:$ bpftool prog show
... 29: xdp tag 992d9ddc835e5629 loaded_at 2020-03-13T16:14:38+0000 uid 0 xlated 176B not jited memlock 4096B map_ids 1
Display the active
xsk_mapkernel memory space allocated by the eBPF program:$ bpftool map
1: xskmap name xsks_map flags 0x0 key 4B value 4B max_entries 6 memlock 4096B
Press Ctrl + C to unmount AF_XDP socket and unload eBPF program
Sanity Check #4: Load and Execute “Native mode” AF_XDP Socket Default XDP_ZEROCOPY¶
Set up two or more ECI nodes according to the AF_XDP Socket (CONFIG_XDP_SOCKETS) guidelines.
Execute a
XDP_RXaction from the precompiled BPF XDP program loaded usingigc.koorigb.koandstmmac.koIntel® Ethernet Controller Linux interface under Native mode withXDP_ZEROCOPYenabled:$ xdpsock -i enp0s30f4 -q 0 -N -z
sock0@enp0s30f4:0 rxdrop xdp-drv pps pkts 1.01 rx 0 0 tx 0 0 sock0@enp0s30f4:0 rxdrop xdp-drv pps pkts 1.00 rx 0 0 tx 0 0 sock0@enp0s30f4:0 rxdrop xdp-drv pps pkts 1.00 rx 0 0 tx 0 0 sock0@enp0s30f4:0 rxdrop xdp-drv pps pkts 1.00 rx 0 0 tx 0 0 ^C sock0@enp0s30f4:0 rxdrop xdp-drv pps pkts 0.47 rx 0 0 tx 0 0
Display the Ethernet interface active eBPF program in “Native mode” with
XDP_ZEROCOPY:$ ip link show dev enp0s30f4
3: enp0s30f4: <BROADCAST,MULTICAST,DYNAMIC,UP,LOWER_UP> mtu 1500 xdp qdisc mq state UP mode DEFAULT group default qlen 1000 link/ether 88:ab:cd:11:01:23 brd ff:ff:ff:ff:ff:ff prog/xdp id 30 tag 992d9ddc835e5629
Display the eBPF program actively exposing the
AF_XDPsocket:$ bpftool prog show
30: xdp tag 992d9ddc835e5629 loaded_at 2020-03-13T16:04:37+0000 uid 0 xlated 176B not jited memlock 4096B map_ids 2
Display the active
xsk_mapkernel memory space allocated by the eBPF program:$ bpftool map
2: xskmap name xsks_map flags 0x0 key 4B value 4B max_entries 6 memlock 4096B
Press Ctrl + C to unmount the
AF_XDPsocket and unload eBPF program.