Action Chunking with Transformers - ACT
Action Chunking with Transformers (ACT) is an end-to-end imitation learning model designed for fine manipulation tasks in robotics, learned directly from real demonstrations. ACT aims to overcome the limitations of imitation learning, where policy errors can compound over time and lead to drifting out of the training distribution. By predicting actions in chunks, ACT effectively reduces the horizon, enabling the system to perform complex tasks such as opening a translucent condiment cup and slotting a battery with high success rates (80-90%) using only 10 minutes of demonstration data. ACT model is proposed as an algorithm component of a system, which focus on learning fine-grained bimanual manipulation with low-cost hardware.
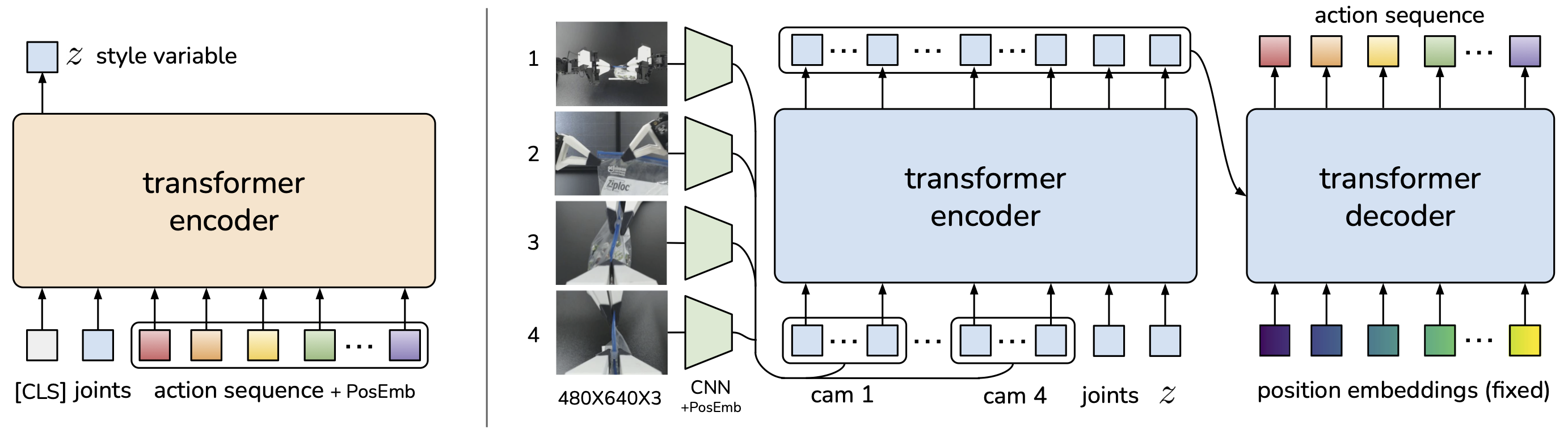
Model Architecture:
Observation Encoder:
Processes high-dimensional observations (e.g., images, sensor data) into a compact representation.
Uses convolutional layers or other feature extraction methods.
Transformer Network:
A transformer-based architecture that models temporal dependencies between action chunks.
Takes the encoded observations and predicts a sequence of action chunks.
Action Decoder:
Converts the predicted action chunks into low-level control commands (e.g., joint torques, gripper actions).
More Information:
Full paper: https://arxiv.org/pdf/2304.13705
Homepage: https://tonyzhaozh.github.io/aloha/
Github link: https://github.com/tonyzhaozh/aloha
Model Conversion
Note
We provide a pretrained checkpoint and also a model conversion script to help you convert model to OpenVINO IR format. Please get the information at the Imitation Learning sample pipeline page Install ACT pipeline of OpenVINO.
Load the trained checkpoint
Attention
Please be sure that the model configuration especially kl_weight, chunk_size, hidden_dim, dim_feedforward, camera_names are same to the configuration while training. Failure to do so will result in a shape mismatch between the model checkpoint and the structure.
# Build the torch model. ACTPolicy definition can be found in policy.py.
# ACT_args is the model configuration dictionary, you can dump it from imitate_episodes.py.
# Please keep the configurations same to the configurations used by training.
from policy import ACTPolicy
policy = ACTPolicy(ACT_args)
policy.eval()
# Load checkpoint weights.
ckpt_path = "./policy_best.ckpt"
state_dict = torch.load(ckpt_path, weights_only=True, map_location=torch.device('cpu'))
policy.load_state_dict(state_dict)
Convert model to PyTorch* jit trace
# construct example input tensors
H = 480
W = 640
CAMERA_NUMS = len(ACT_args.camera_names)
qpos = torch.rand((1, 14))
image = torch.rand((1, CAMERA_NUMS, 3, H, W))
# Convert to jit trace
traced_policy = torch.jit.trace(policy, example_inputs=(qpos, image))
# Get output tensor name for OpenVINO conversion (in this case, we get ['qpos', 'tensor.1'])
graph = traced_policy.graph
input_names = [inp.debugName() for inp in graph.inputs() if inp.debugName() != 'self.1']
print("Input tensor names:", input_names)
Convert jit trace to OpenVINO IR and save model
# Save converted model (input tensor names are required)
ov_policy = ov.convert_model(traced_policy, input={'qpos':(1,14), 'tensor.1':(1,CAMERA_NUMS,3,H,W)}) # specify input shape to get better performance, or use dynamic shape (1,CAMERA_NUMS,3,-1,-1) to adapt to changing sizes during inference.
ov.save_model(ov_policy, "output_model.xml")