Monocular Depth Estimation: Depth Anything V2
Monocular depth estimation is the process of predicting depth information from a single image, which is a challenging task due to the inherent ambiguity and lack of explicit 3D cues in 2D images. Despite these challenges, advancements in computer vision and deep learning have made monocular depth estimation increasingly viable. Here’s an overview of how it works, along with its significance in autonomous driving, mobile robots, and humanoid robots.
Typically, monocular depth estimation brings such common features as below:
Deep Learning Models: Modern monocular depth estimation primarily relies on deep learning. These models are trained on large datasets containing images with corresponding depth maps, learning to infer depth from visual cues such as texture, shading, and object size.
Feature Extraction: The process begins with extracting features from the input image using DNN layers. These features capture essential information about the scene’s structure and objects.
Depth Prediction: The extracted features are then processed by subsequent network layers to predict a depth map. This map assigns a depth value to each pixel, indicating the distance from the camera to the scene elements.
Post-Processing: Some methods apply post-processing techniques to refine the depth map, addressing issues like noise and discontinuities.
Monocular depth estimation is a powerful tool that leverages deep learning to infer 3D information from 2D images. Its applications in autonomous driving, mobile robots, and humanoid robots are significant, offering cost-effective, efficient, and versatile solutions for navigation, interaction, and scene understanding.
Here is a list of benefits monocular depth estimation can deliver to robotics scenarios:
Autonomous Driving
Cost-Effectiveness: Monocular depth estimation provides a cost-effective alternative to expensive sensors like LiDAR, making it attractive for mass-market autonomous vehicles.
Obstacle Detection: It enhances the vehicle’s ability to detect and understand the distance to obstacles, which is crucial for safe navigation and collision avoidance.
Scene Understanding: Depth estimation contributes to better scene understanding, aiding in tasks like lane detection, traffic sign recognition, and pedestrian detection.
Mobile Robots
Navigation: For mobile robots, monocular depth estimation enables navigation in environments where stereo cameras or LiDAR might be impractical due to size, weight, or cost constraints.
SLAM: It assists in simultaneous localization and mapping (SLAM) by providing depth information that helps in building and updating maps of the environment.
Autonomous Exploration: Depth estimation allows robots to explore unknown environments autonomously, making decisions based on perceived distances to objects and obstacles.
Humanoid Robots
Interaction with Environment: Humanoid robots benefit from depth estimation by gaining a better understanding of their surroundings, which is essential for tasks like object manipulation and human interaction.
Balance and Locomotion: Accurate depth perception helps humanoid robots maintain balance and navigate complex terrains, improving their mobility and stability.
Human-Robot Collaboration: Depth information enhances the robot’s ability to interpret human actions and gestures, facilitating more natural and effective collaboration.
Depth Anything V2, is an active powerful foundation model for monocular depth estimation. It is capable of
providing robust and fine-grained depth prediction,
supporting extensive applications with varied model sizes (from 25M to 1.3B parameters),
being easily fine-tuned to downstream tasks as a promising model initialization.
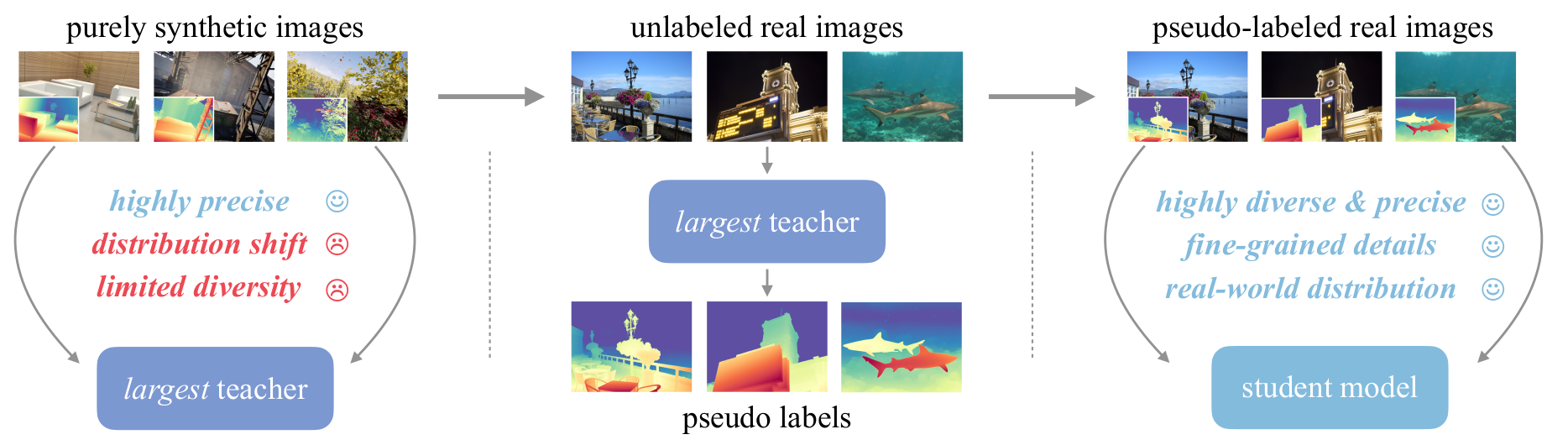
Model Architecture:
Train a reliable teacher model based on DINOv2-G purely on high-quality synthetic images.
Produce precise pseudo depth on large-scale unlabeled real images.
Train final student models on pseudo-labeled real images for robust generalization
More Information:
Full paper: https://arxiv.org/html/2406.09414v1
Github link: https://github.com/DepthAnything/Depth-Anything-V2
Model Conversion
The Depth-Anything-V2 model is trained using PyTorch* but can achieve optimized inference performance on Intel devices using Intel® OpenVINO™. To enable this, the PyTorch* model must first be converted to the Intel® OpenVINO™ IR format.
Table of Contents
Export Depth-Anything-V2 to ONNX
Before converting the model to OpenVINO IR, it is best practice to first export the PyTorch model to ONNX format.
The repository Depth-Anything-ONNX provides a simple command-line tool, dynamo.py, based on Typer to facilitate this conversion.
Installation
Ensure that all required dependencies are installed before proceeding with the conversion (python 3.11 or higher is required).
pip install -r requirements.txt
Exporting the model to ONNX
Use the following command to export the Depth-Anything-V2 model to ONNX format:
python dynamo.py export --encoder vitb --output weights/vitb.onnx --use-dynamo -h 518 -w 518
--encoder vitb: Specifies the encoder type (e.g.,vitbfor Vision Transformer-B).--output weights/vitb.onnx: Defines the output path for the ONNX model.--use-dynamo: Enables the use oftorch.compilevia Dynamo for optimized tracing.-h 518 -w 518: Specifies the height and width of the input images.
Hint
If you encountered a downloading error, please refer to Troubleshooting
Convert ONNX to OpenVINO IR
Ensure OpenVINO is Installed
Note
Make sure OpenVINO is installed by following the guide: Install OpenVINO via pip
Once the model is in ONNX format, it can be converted to OpenVINO’s Intermediate Representation (IR) format using OpenVINO’s command-line model conversion tool, ovc.
Convert ONNX to OpenVINO IR using ovc
The ovc tool simplifies the process of converting an ONNX model to OpenVINO IR format.
Run the following command to perform the conversion:
ovc vitb.onnx
By default, this command converts the ONNX model to FP16 IR format, generating the following files:
vitb.xml: Defines the model topology.vitb.bin: Stores the model weights and binary data.
If you need an FP32 precision model, add the following parameter to the ovc conversion command:
ovc vitb.onnx --compress_to_fp16=False