Feature Extraction Model: SuperPoint
SuperPoint is a self-supervised framework for interest point detection and description in images, suitable for a large number of multiple-view geometry problems in computer vision. As opposed to patch-based neural networks, SuperPoint, as a fully-convolutional model, operates on full-sized images and jointly computes pixel-level interest point locations and associated descriptors in one forward pass. The model introduces Homographic Adaptation, a multi-scale, multi-homography approach for boosting interest point detection repeatability and performing cross-domain adaptation (e.g., synthetic-to-real). Besides, the model is able to repeatedly detect a much richer set of interest points than the initial pre-adapted deep model and any other traditional corner detector. The final system gives a state-of-the-art homography estimation results comparing the traditional feature extraction algorithms such as LIFT, SIFT and ORB.
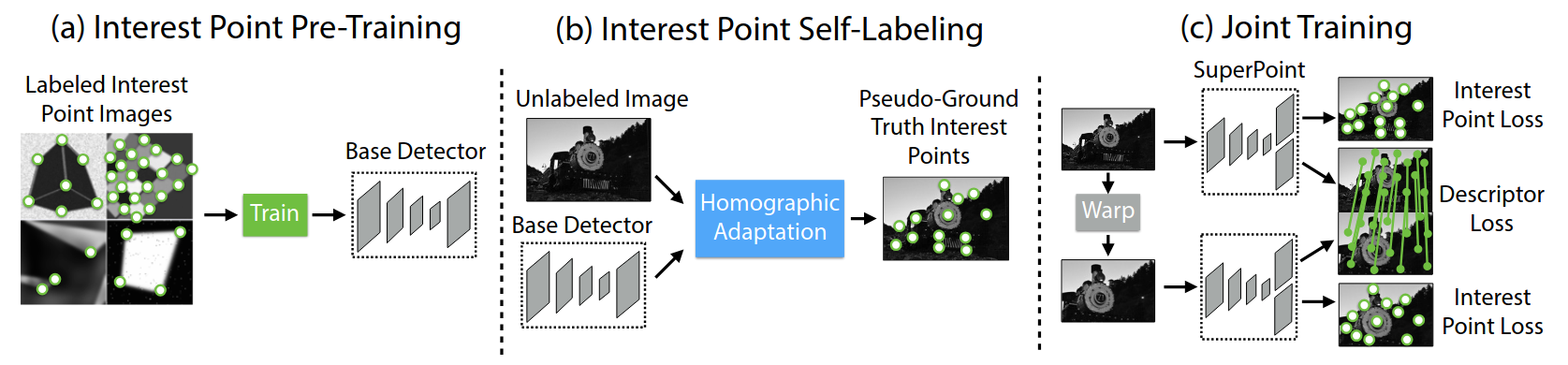
Model Architecture:
Shared Encoder:
The model uses a shared convolutional neural network (CNN) encoder to process the input image.
This encoder extracts feature maps that are used for both keypoint detection and descriptor generation.
Detector Head:
The detector head takes the feature maps from the shared encoder and predicts keypoint locations.
It outputs a probability heatmap where each pixel’s value represents the likelihood of being a keypoint.
Descriptor Head:
The descriptor head also takes the feature maps from the shared encoder and generates dense descriptors for each pixel.
These descriptors are typically 256-dimensional vectors that describe the local image patch around each pixel.
More Information:
Full paper: https://arxiv.org/pdf/1712.07629
Github link: https://github.com/rpautrat/SuperPoint
Model Conversion
The SuperPoint model is trained using TensorFlow but can achieve optimized inference performance on Intel devices using Intel® OpenVINO™. To enable this, the TensorFlow model can be directly converted to the Intel® OpenVINO™ IR format.
Table of Contents
Download the Pretrained Model
The pretrained model sp_v6.tgz can be downloaded directly from the repository: SuperPoint Pretrained Models
After downloading, extract the model using the following command:
$ tar -xvzf sp_v6.tgz
Convert TensorFlow Model to OpenVINO IR
Ensure OpenVINO is Installed
Note
Make sure OpenVINO is installed by following the guide: Install OpenVINO via pip
Convert the Model using OpenVINO Conversion Tool
Since the model is in TensorFlow format, it can be converted to OpenVINO’s Intermediate Representation (IR) format using OpenVINO’s command-line model conversion tool, ovc.
Run the following command to perform the conversion:
$ cd sp_v6
$ ovc ./ --input [1,1280,720,1]
--input [1,1280,720,1]: Specifies the input dimensions of the model. The parameters represent:
1: Batch size (process 1 image at a time).
1280: Height of the input image (adjust according to your input data).
720: Width of the input image (adjust according to your input data).
1: Number of channels (1 for grayscale images; use 3 for color images).
By default, this command converts the model to FP16 IR format, generating the following files in the current directory:
sp_v6.xml: Defines the model topology (structure and layers).
sp_v6.bin: Contains the model weights and binary data.
If you need an FP32 precision model, add the following parameter to the ovc conversion command:
$ ovc ./ --input [1,1280,720,1] --compress_to_fp16=False
Additional Notes
Converting to FP16 (default) generally results in better performance on Intel devices (especially those with AVX-512 support) while maintaining a good balance of accuracy.
FP32 models should be used if you need higher accuracy but are willing to trade some inference speed for it.