Real-Time Scheduling on Linux IA64¶
Over time, two major approaches have been taken in the open-source software community to bring real-time requirements into Linux:
Improve the Linux kernel itself so that it matches real-time requirements, by providing bounded latencies, real-time APIs, etc. This is the approach taken by the mainline Linux kernel and the PREEMPT_RT project.
Add a layer below the Linux kernel (e.g. OS Real-time extension) that will handle all the real-time requirements, so that the behavior of Linux doesn’t affect real-time tasks. This is the approach taken by the Xenomai project.
General definitions¶
Both approaches aim to bring the “lowest thread scheduling latency” under Linux multi-cpu RT and non-RT software execution context.

Note
Scheduling latency = interrupt latency + handler duration + scheduler latency + scheduler duration
IA64 interrupt definitions¶
Interrupts can be described as an “immediate response to hardware events”. The execution of this response is typically called an Interrupt Service Routine (ISR). In the process of servicing the ISR, many latencies may occur. These latencies are divided into two components, based on their originating source as follows:
Software Interrupt Latencycan be predicted based on the system interrupt-disable time and the size of the system ISR (Interrupt Service Routine) prologue. This is the code that saves the registers manually, it also performs operations before the start of interrupt handler.Hardware Interrupt Latencyreflects the time required for operations such as retirement of in-flight instructions, determining address of interrupt handler, and storing all CPU registers.

Various Types of Interrupt sources:
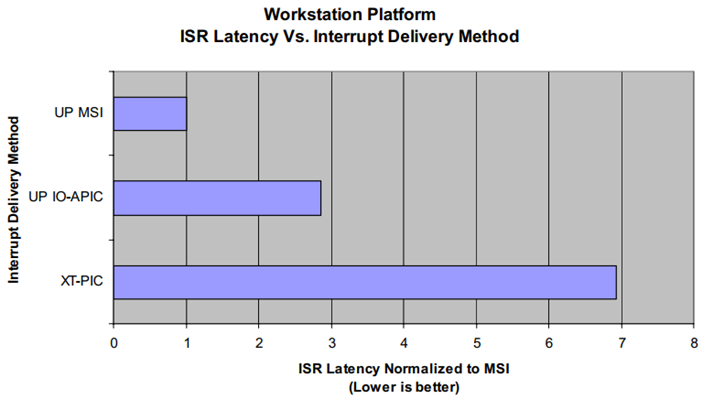
- Legacy Interrupts XT-PIC
side-bandsignals backward compatible with PC/AT peripheral IRQs (ie. PIRQ/INTR/INTx).- Message-Signaled Interrupts (MSI)
in-bandmessages which target a memory address send data along with the interrupt message. MSI exhibit the following characteristics:MSI messages achieve the lowest latency possible. The CPU begins executing the MSI Interrupt Service Routine (ISR) immediately after it finishes its current instruction.
MSI messages appear as a Posted Memory Write transaction. As such, a PCI function can request up to 32 MSI messages.
MSI messages send data along with the interrupt message but do not receive any hardware acknowledgment.
MSI messages write specific device addresses and send transactions to the Local IO-APIC of the CPU which it is assigned.
- NMI – Non-Maskable Interrupts
Typically system events (e.g. power-button, watchdog timer, …). NMI exhibit the following characteristics:
NMI usually originate from Power-Control Unit (PCU) or IA64 firmware sources.
- SCI – System Control Interrupt
Used by hardware to notify the OS through ACPI 5.0, PCAT, or IASOC (Hardware-Reduced ACPI)
- SMI – System Management Interrupt
Generated by the power management hardware on the board. SMI exhibit the following characteristics:
SMI processing can last for hundreds of microseconds and are the highest priority interrupt (even higher than the NMI).
The CPU receives an SMI whenever the mode is changed (e.g. thermal sensor events, chassis open) and jumps to a hard-wired location in a special SMM address space (System Management RAM).
The SMI cannot be intercepted by user-code since there are no vectors in the CPU. This effectively renders SMI interrupts “invisible” to the Operating System.
Linux multi-threading definitions¶
- User-space process
Created when the POSIX
fork()command is called and is comprised of:An address space (e.g vma), which contains the program code, data, stack, shared libraries, etc.
One thread, that starts executing the
main()function.
- User-thread
Can be created/added inside an existing process, using the POSIX
pthread_create()command.User-threads run in the same address space as the initial process thread.
User-threads start executing a function passed as argument to
pthread_create().
- Kernel-thread
Can be created/added inside an kernel module, using the POSIX
kthread_create()command.Kernel-threads are light-weight processes cloned from process 0 (the swapper), which share its memory map and limits, but contain a copy of its file descriptor table.
Kernel-threads run in the same address space as the initial process thread.
General Linux Timer definitions¶
Isochronous applications aim to complete their tasks at exact defined times. Unfortunately the Linux standard timer does not generally meet the required cycle deadline resolution and/or precision.
For example, a typical timer function in Linux such as the gettimeofday() system call will return clock time with microsecond precision, where nanosecond timer precision is often desirable.
To mitigate this limitation, additional POSIX APIs have been created that provide more precise timing capability. These APIs are described below.
- Timer cyclic-task scheduling
Within the PREEMPT_RT scheduling context, a cyclic-task timer can be created with a given clock-domain using the POSIX
timer_create()command. This timer exhibits the following characteristics:Delivery of signals at the expiry of POSIX timers can not be done in the hard interrupt context of the high resolution timer interrupt.
The signal delivery in both these cases must happen in thread context due to locking constraints that results in long latencies.
//POSIX timers int timer_create(clockid_t clockid, struct sigevent *sevp, timer_t *timerid);
- Task nanosleep cyclic scheduling wake-up
Within the COBALT task scheduling context, cyclic-task timers can be created with a given clock-domain using the POSIX
clock_nanosleep()command. This timer exhibits the following characteristics.Clock_nanosleep does not work on signaling mechanism, which is why clock_nanosleep does not suffer above latency problem.
The task sleep-state timer expiry is executed in the context of the high resolution timer interrupt.
It is recommended if the an application is not using asynchronous signal handler better to use clock_nanosleep.
//Clock_nanosleep int clock_nanosleep(clockid_t clock_id, int flags, const struct timespec *request, struct timespec *remain);
PREEMPT_RT preemptive and priority scheduling on Linux OS runtime¶
The PREEMPT_RT project is an open-source framework under GPLv2 License lead by Linux kernel developers.
The goal is to gradually improve the Linux kernel regarding real time requirements and to get these improvements merged into the mainline kernel PREEMPT_RT development works very closely with the mainline development.
Many of the improvements designed, developed, and debugged inside PREEMPT_RT over the years are now part of the mainline Linux kernel. The project is a long-term branch of the Linux kernel that ultimately should disappear as everything will have been merged.
Setting low-latency Interrupt SW handling¶
PREEMPT_RT enforces fundamental SW design rules to reach full-preemptive and low-latency scheduling by evangelizing “No non-threaded IRQ nesting” development practices across kernel code and numerous drivers/modules code-base.
A top-half, started by the CPU as soon as interrupts are flagged, is supposed to complete as quickly as possible:
The interrupt controller (APIC, MSI, etc) receives an event from hardware that triggers an interrupt.
The processor switches modes, saves registers, disables preemption, and disables IRQs.
Generic Interrupt vector code is called.
At this point, the context of the interrupted activity is saved.
Lastly, the relevant ISR pertaining to the interrupt event is identified and called.
A bottom-half, scheduled by the top-half which starts as soft-IRQs, tasklets, or work queues tasks, is to be completed by ISR execution: Real-time critical interrupts, bottom-half should be used very carefully: ISR execution is undeterministic, as function of all other interrupts top-half. Non-Realtime interrupts, bottom-half shall be threaded to reduce the duration of non-preemptible.

Multi-thread scheduling Preemption CAN happen when:
High priority task wakes up as a result of an interrupt
Time slice expiration
System call results in task sleeping
Multi-thread scheduling Preemption CAN NOT happen when kernel-code critical section:
Interrupts explicitly disabled
Preemption explicitly disabled
Spinlock critical sections unless using preemptive spinlocks
Setting Preemptive and Priority Scheduling policies¶
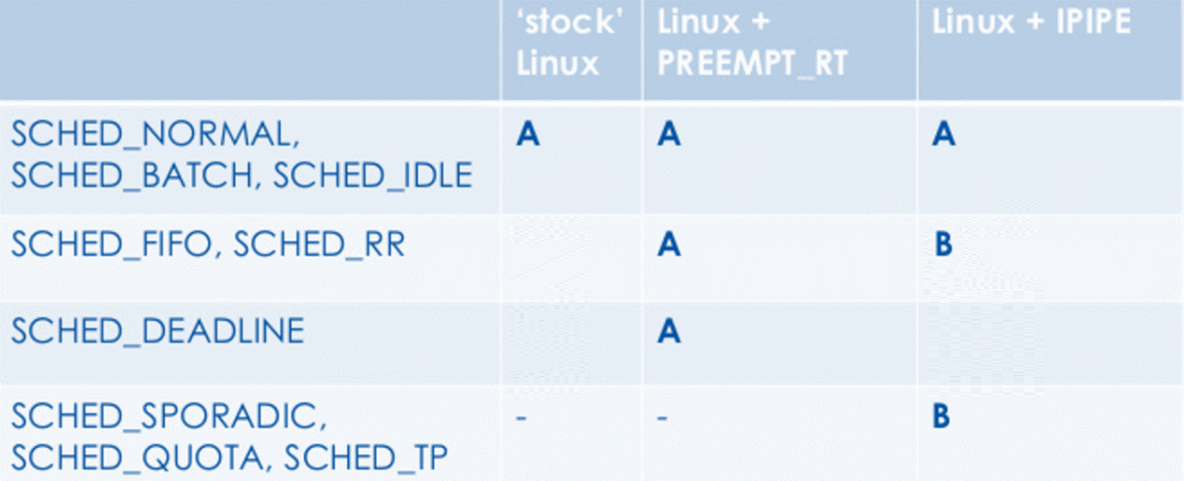
The standard Linux kernel includes different scheduling policies, as described in the manpage for sched. There are three policies relevant for real-time tasks:
SCHED_FIFOimplements a first-in, first-out scheduling algorithm.When a
SCHED_FIFOtask starts running it continues to run until either it is preempted by a higher priority thread, it is blocked by an I/O request or it calls yield function.All other tasks of lower priority will not be scheduled until
SCHED_FIFOtask release the CPU.Two
SCHED_FIFOtasks with same priority cannot preempt each other.
SCHED_RRis identical to theSCHED_FIFOscheduling, the only difference will be the way it handles the processes with the same priority.The scheduler assigns each
SCHED_RRtask a time slice, when the process exhausts its time slice the scheduler moves it to the end of the list of processes at its priority.In this manner,
SCHED_RRtask of a given priority are scheduled in round-robin among themselves.If there is only one process at a given priority, the RR scheduling is identical to the FIFO scheduling.
SCHED_DEADLINEis implemented using Earliest Deadline First (EDF) scheduling algorithm, in conjunction with Constant Bandwidth Server (CBS).SCHED_DEADLINEpolicy uses three parameters to schedule tasks -Runtime,DeadlineandPeriod.A
SCHED_DEADLINEtask gets “runtime” nanoseconds of CPU time for every “period” nanoseconds. The “runtime” nanoseconds should be available within “deadline” nanoseconds from the period beginning.Tasks are scheduled using EDF based on the scheduling deadlines(these are calculated every time when the task wakes up).
Task with the earliest deadline is executed.
SCHED_DEADLINEthreads are the highest priority (user controllable) threads in the system.If any
SCHED_DEADLINEthread is runnable, it will preempt any thread scheduled under one of the other policies.
Priority Inheritance assume that the lock (e.g. spin_lock, mutex, … ) inherits the priority of the process thread waiting for the lock with greatest priority.
CONFIG_PREEMPT_RT_FULL provides priority-inheritance capabilities to rtmutex, spin_lock, and mutex code:
A process with a low priority might hold a lock needed by a higher priority process, effectively reducing the priority of this process.
chrt runtime Processes Linux scheduling policies¶
On Linux, the chrt command can be used to set the real-time attributes of a process, such as policy and priority
Syntax to set scheduling policy to FIFO based priority values for
SCHED_FIFOcan be between 1 and 99:chrt --fifo --pid <priority> <pid>Below example will set scheduling attribute to
SCHED_FIFOfor the process with pid 1823:root@intel-corei7-64:~# chrt --fifo --pid 99 1823
Syntax to set scheduling policy to round-robin based priority values for
SCHED_RRcan be between 1 and 99chrt -rr --pid <priority> <pid>Below example will set the scheduling attribute to
SCHED_RRand priority 99 for the process with pid 1823root@intel-corei7-64:~# chrt --rr --pid 99 1823
Syntax to set scheduling policy to deadline-based priority value for
SCHED_DEADLINEis 0 runtime <= deadline <= periodchrt --deadline --sched-runtime <nanoseconds> \ --sched-period <nanoseconds> \ --sched-deadline <nanoseconds> \ --pid <priority> <pid>
Below example will set scheduling attribute to
SCHED_DEADLINEfor the process with pid 472. The runtime, deadline and period are given in nanoseconds.root@intel-corei7-64:~# ps f -g 0 -o pid,policy,rtprio,cmd PID POL RTPRIO CMD 1 TS - /sbin/init nosoftlockup noht 3 185 TS - /lib/systemd/systemd-journald 209 TS - /lib/systemd/systemd-udevd 472 RR 99 /usr/sbin/acpid 476 TS - /usr/sbin/thermald --no-daemon --dbus-enable 486 TS - /usr/sbin/jhid -d
Execute below command to change the policy to
SCHED_DEADLINE(#6)root@intel-corei7-64:~# chrt --deadline --sched-runtime 10000 \ --sched-deadline 100000 \ --sched-period 1000000 \ --pid 0 472
Execute below command to see change in the policy of a task
root@intel-corei7-64:~# ps f -g 0 -o pid,policy,rtprio,cmd PID POL RTPRIO CMD 1 TS - /sbin/init nosoftlockup noht 3 185 TS - /lib/systemd/systemd-journald 209 TS - /lib/systemd/systemd-udevd 472 #6 0 /usr/sbin/acpid 476 TS - /usr/sbin/thermald --no-daemon --dbus-enable 486 TS - /usr/sbin/jhid -d
Condensing this information in a table:
Prio
Names
99
posixcputmr, migration
50
All IRQ handlers except
39-s-mmc0and42-s-mmc1. E.g.367-enp2s0deals with one of the network interfaces49
IRQ handlers
39-s-mmc0and42-s-mmc11
i915/signal,
ktimersoftd,rcu_preempt,rcu_sched,rcub,rcuc0
The rest of the tasks currently running
The highest priority real-time tasks in this system are the timers and migration threads, with prio 99. The lowest priority real-time tasks are
sched_setscheduler() and sched_setattr() Processes runtime Linux scheduling policies¶
The sched_setscheduler function can be used to change the active scheduling policy. The below values can be used to set real-time scheduling policies:
SCHED_FIFO
SCHED_RR
Note
Non-real-time scheduling policies such as SCHED_OTHER, SCHED_BATCH, and SCHED_IDLE are also available. There is no support for deadline scheduling policy in sched_setscheduler function.
sched_setschedulerfunction sets theSCHED_FIFOorSCHED_RRscheduling policy and priority for a real-time thread policyint sched_setscheduler(pid_t pid, int policy, const struct sched_param *param);
The example below will configure the running process to use
SCHED_RRscheduling with priority as 99:struct sched_param param_rr; memset(¶m_rr, 0, sizeof(param_rr)); param_rr.sched_priority = 99; pid_t pid = getpid(); if (sched_setscheduler(pid, SCHED_RR, ¶m_rr)) perror("sched_setscheduler error:");
The example below will configure the running process to use
SCHED_FIFOscheduling with priority as 99:struct sched_param param_fifo; memset(¶m_fifo, 0, sizeof(param_fifo)); param_fifo.sched_priority = 99; pid_t pid = getpid(); if (sched_setscheduler(pid, SCHED_FIFO, ¶m_fifo)) perror("sched_setscheduler error:");
sched_setattrfunction setsSCHED_DEADLINEscheduling policy (from kernel version 3.14.)int sched_setattr(pid_t pid, struct sched_attr *attr, unsigned int flags);
In the below example the process in execution is assigned with the
SCHED_DEADLINEpolicy. The process gets a runtime of 2 milliseconds for every 9 milliseconds period. The runtime milliseconds should be available within 5 milliseconds of deadline from the period beginning.#define _GNU_SOURCE #include <stdint.h> #include <stdio.h> #include <unistd.h> #include <sys/syscall.h> #include <sched.h> #include <string.h> #include <linux/sched.h> #include <sys/types.h> struct sched_attr { uint32_t size; uint32_t sched_policy; uint64_t sched_flags; int32_t sched_nice; uint32_t sched_priority; uint64_t sched_runtime; uint64_t sched_deadline; uint64_t sched_period; }; int sched_setattr(pid_t pid, const struct sched_attr *attr, unsigned int flags) { return syscall(__NR_sched_setattr, pid, attr, flags); } int main() { unsigned int flags = 0; int status = -1; struct sched_attr attr_deadline; memset(&attr_deadline, 0, sizeof(attr_deadline)); pid_t pid = getpid(); attr_deadline.sched_policy = SCHED_DEADLINE; attr_deadline.sched_runtime = 2*1000*1000; attr_deadline.sched_deadline = 5*1000*1000; attr_deadline.sched_period = 9*1000*1000; attr_deadline.size = sizeof(attr_deadline); attr_deadline.sched_flags = 0; attr_deadline.sched_nice = 0; attr_deadline.sched_priority = 0; status = sched_setattr(pid,&attr_deadline,flags) if(status) perror("sched_setscheduler error:"); return 0; }
pthread POSIX Linux runtime scheduling APIs¶
The scheduling policy for threads can be set using the pthread functions pthread_attr_setschedpolicy, pthread_attr_setschedparam, pthread_attr_setinheritsched.
Creating a realtime thread using FIFO scheduling policy and POSIX pthread functions can be broken down into simple steps:
To create a thread using FIFO scheduling initialize the
pthread_attr_t(thread attribute object) object usingpthread_attr_initfunction.pthread_attr_t attr_fifo; pthread_attr_init(&attr_fifo) ;
After initialization, set the thread attributes object referred to by
attr_fifoto SCHED_FIFO (FIFO scheduling policy) usingpthread_attr_setschedpolicy.pthread_attr_setschedpolicy(&attr_fifo, SCHED_FIFO);
Set the priority (can take values between 1-99 for FIFO scheduling) of the thread using the
sched_paramobject and copy the parameter values to thread attribute usingpthread_attr_setschedparam.struct sched_param param_fifo; param_fifo.sched_priority = 92; pthread_attr_setschedparam(&attr_fifo, ¶m_fifo);
Set the inherit-scheduler attribute of the thread attribute. The inherit-scheduler attribute determines if new thread takes scheduling attributes from the calling thread or from the attr. To use the scheduling attribute used in attr call the function
pthread_attr_setinheritschedusingPTHREAD_EXPLICIT_SCHED.pthread_attr_setinheritsched(&attr_fifo, PTHREAD_EXPLICIT_SCHED);
In the next step create the thread by calling
pthread_createfunctionpthread_t thread_fifo; pthread_create(&thread_fifo, &attr_fifo, thread_function_fifo, NULL);
All together, the simplest preemptible multi-threading application can be achieved under FIFO scheduling policy as followed :
#include <pthread.h> #include <stdio.h> void *thread_function_fifo(void *data) { printf("Inside Thread\n"); return NULL; } int main(int argc, char* argv[]) { struct sched_param param_fifo; pthread_attr_t attr_fifo; pthread_t thread_fifo; int status = -1; memset(¶m_fifo, 0, sizeof(param_fifo)); status = pthread_attr_init(&attr_fifo); if (status) { printf("pthread_attr_init failed\n"); return status; } status = pthread_attr_setschedpolicy(&attr_fifo, SCHED_FIFO); if (status) { printf("pthread_attr_setschedpolicy failed\n"); return status; } param_fifo.sched_priority = 92; status = pthread_attr_setschedparam(&attr_fifo, ¶m_fifo); if (status) { printf("pthread_attr_setschedparam failed\n"); return status; } status = pthread_attr_setinheritsched(&attr_fifo, PTHREAD_EXPLICIT_SCHED); if (status) { printf("pthread_attr_setinheritsched failed\n"); return status; } status = pthread_create(&thread_fifo, &attr_fifo, thread_function_fifo, NULL); if (status) { printf("pthread_create failed\n"); return status; } pthread_join(thread_fifo, NULL); return status; }
On Glibc 2.25 (and onward) POSIX pthread condition variable (e.g. pthread_cond*) to define priority-inheritance :
rt_mutexcannot be in a state with waiters and no owner
pthread_cond*APIs re-implemented signal threads for_wait()and_signal()operations using not PI-aware futex operations to put the calling waiter.
Note
references https://wiki.linuxfoundation.org/realtime/events/rt-summit2016/pthread-condvars
kthread Read-Copy Update (RCU)¶
Read-Copy Update (RCU) APIs are used heavily in the Linux code to synchronize kernel threads without locks
Excellent for read-mostly data where staleness and inconsistency OK
Good for read-mostly data where consistency is required
Can be OK for read-write data where consistency is required
Might not be best for update-mostly consistency-required data
Provide existence guarantees that are useful for scalable updates.
Tuning RCU is part of any deterministic and synchronized data-segmentation:
CONFIG_PREEMPT_RCUReal-Time Preemption and RCU readers manipulate CPU-local counters to limit blocking within RCU read-side critical sections https://lwn.net/Articles/128228/
CONFIG_RCU_NOCB_CPURCU Callback Offloading directed to the CPUs of your choice
CONFIG_RCU_BOOSTRCU priority boosting tasks blocking the current grace period for more than half a second to real-time priority level 1.
CONFIG_RCU_KTHREAD_PRIOandCONFIG_RCU_BOOST_DELAYprovide additional control of RCU priority boosting
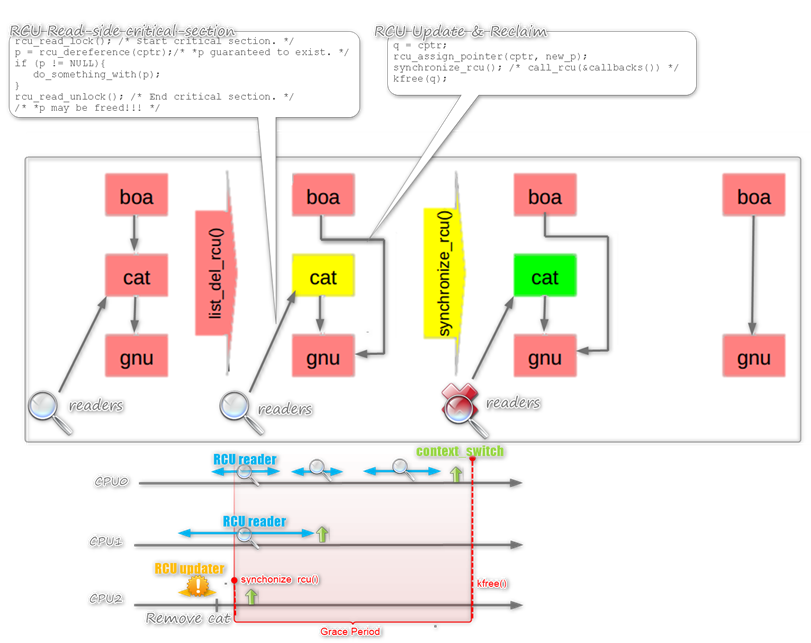
Pointer to RCU-protected object guaranteed exist throughout RCU read-side critical section using very light weight primitives:
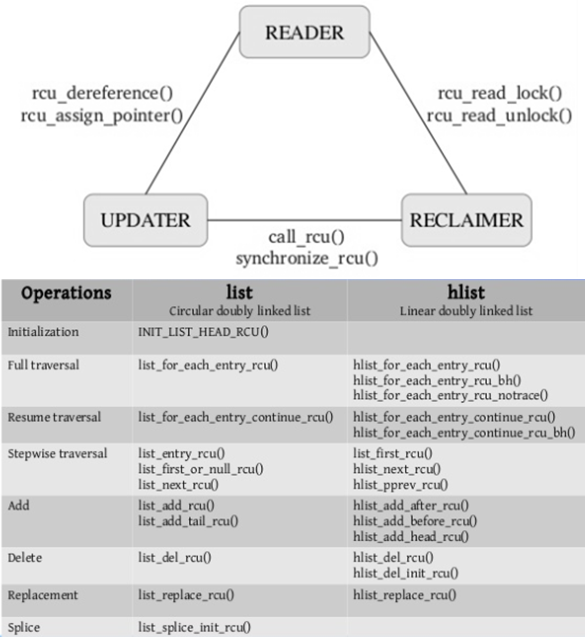
All RCU writers must wait for an RCU grace period before Reclaim, to elapse between making something inaccessible to readers and freeing it.
spinlock(&updater_lock); q = cptr; rcu_assign_pointer(cptr, new_p); spin_unlock(&updater_lock); synchronize_rcu(); /* Wait for grace period. */ kfree(q);RCU grace period for all pre-exiting readers to complete their RCU read-side critical sections Grace period begins after synchronize_rcu() call and ends after all CPUs execute a context switch
Setting POSIX thread virtual memory allocation (vma)¶
Linux process memory management is considered as one of the important and critical aspects of PREEMPT_RT Linux runtime as compared to a standard Linux runtime. From kernel scheduling point of view it makes no difference as processes and Threads represents each one as task_struct kernel structure of type running. However, from scheduling latency standpoint a Process context-switch is significantly longer than a User-thread context-switch within the same process, as process switching needs to flush TLB.

There are different algorithms for memory management designed to optimize both the runnable processes and improve system performance. For instance, when a processes which need the full memory page that kernel-allocated mmap() returns, or only part of a page, memory management works along with the scheduler to optimally utilize resources.
Let’s explore three main areas of memory management:
- Memory Locking
Memory locking is essential as part of the initialization the program. Most of the real-time processes lock the memory throughout their execution. Memory locking API
mlockandmlockallfunctions can be used by applications to lock the memory whilemunlockandmunlockallare used to unlock the memory pages (virtual address space) of the application into the main memory.mlock(void *addr,size_t len)- This function locks a selected region(starting from addr to len bytes) of address space of the calling process into memory.mlockall(int flags)- This function locks all of the process address space. MCL_CURRENT, MCL_FUTURE and MCL_ONFAULT are different flags available.munlock(void *addr,size_t len)- This function will unlock a specified region of a process address space.munlockall(void)- This system call will unlock all of the process address space.
Locking of memory will make sure that the application pages are not removed from main memory during crisis. This will also ensures that page-fault do not occur during RT critical operations which is very important.
- Stack Memory
Each of the threads within an application have their own stack. The size of the stack can be specified by using the pthread function
pthread_attr_setstacksize().Syntax of
pthread_attr_setstacksize(pthread_attr_t *attr, size_t stacksize):attr- thread attribute structure.stacksize- in bytes, should not be less than PTHREAD_STACK_MIN (16384 bytes). The default stack size on Linux is 2MB.
If the size of the stack is not set explicitly then the default stack size is allocated. If the application uses a large number of RT threads, it is advised to use smaller stack size than default size.
- Dynamic Memory Allocation
Dynamic memory allocation of memory is not suggested for RT threads during the execution is in RT critical path as this increases the chance of page faults. It is suggested to allocate the required memory before the start of RT execution and lock the memory using the
mlock/mlockallfunctions. In the below example the thread function is trying to dynamically allocate memory to a thread local variable and try to access data stored in theses random locations.#define BUFFER_SIZE 1048576 void *thread_function_fifo(void *data) { double sum = 0.0; double* tempArray = (double*)calloc(BUFFER_SIZE, sizeof(double)); size_t randomIndex; int i = 50000; while(i--) { randomIndex = rand() % BUFFER_SIZE; sum += tempArray[randomIndex]; } return NULL; }
Setting NoHz (Tickless) Kernel¶
The Linux kernel used to send the scheduling clock interrupt (ticks) to each CPU every jiffy, in order to shift CPU attention periodically towards multiple task. Where a jiffy is a very short period of time, which is determined by the value of the kernel Hz.
It traditionally being unused in cases of:
Input power constrained device like mobile device, triggering clock interrupt can drain its power source very quickly even if it is idle.
Virtualization, multiple OS instance might find that half of its CPU time is consumed by unnecessary scheduling clock interrupts.
… many more
A tickless kernel inherently reduces the number of scheduling clock interrupt, which helps to improve energy efficiency and reducing Linux runtime scheduling jitter.
Below are the three contexts where one needs to look for configuring scheduling-clock interrupts to improve energy efficiency:
- CPU with Heavy Workload
CONFIG_HZ_PERIODIC=y(for older kernelsCONFIG_NO_HZ=n) There are situations when CPU with heavy workloads with lots of tasks that use very short time of CPU and having very frequent idle periods, but these idle periods are also quite short (order of tens or hundreds of microseconds). Reducing scheduling-clock ticks will have reverse effect of increasing the overhead of switching to and from idle and transition between user and kernel execution.- CPU in idle
CONFIG_NO_HZ_IDLE=yprimary purpose of a scheduling-clock interrupt is to force a busy CPU to shift its attention among multiple tasks. But an idle CPU, no tasks to shifts its attention, therefore sending scheduling-clock interrupt is of no use. Instead, configure tickless kernel to avoid sending scheduling-clock interrupts to idle CPUs, thereby improving energy efficiency of the systems. This mode can be disable from boot command-line by specifyingnohz=off. By default, kernel boot withnohz=on.- CPU with Single Task
CONFIG_NO_HZ_FULL=yIn a case where CPU predefined with only one task to do, there is no point of sending scheduling-clock interrupt to switch task. So, in order to avoid sending-clock interrupt to this kind of CPUs, below configuration setting in Kconfig of Linux kernel will be useful.
Setting High Resolution Timers thread¶
Timer resolution has been progressively improved by the Linux.org community to offer a more precise way of waking up the system and process data at more accurate intervals:
Initially Unix/Linux systems used timers with a frequency of 100Hz (i.e. 100 timer events per second/one event every 10ms).
Linux version 2.4, i386 systems started using timers with frequency of 1000Hz (i.e. 1000 timer events per second/one event every 1ms). The 1ms timer event improves minimum latency and interactivity but at the same time it also incurs higher timer overhead.
Linux kernel version 2.6 timer frequency was reduced to 250Hz (i.e. 250 timer events per second/one event every 4ms) to reduce timer overhead.
Finally Linux kernel streamlined high-resolution timers nanosecond precision thread usage by adding
CONFIG_HIGH_RES_TIMERS=ykernel builtin driver.
One can also examine the timer_list per cpu cores from /proc/timer_list file system as below :
.resolution value of 1 nanosecond, clock supports high resolution.
event_handler is set to hrtimer_interrupt, this represents high resolution timer feature is active.
.hres_active has a value of 1, this means high resolution timer feature is active.
Note
A resolution of 1ns is not resonable. This only tells, that the system uses HRTs. The usual resolution of HRTs on modern systems is in the micro seconds.
root@intel-corei7-64:~#cat /proc/timer_list | grep 'cpu:\|resolution\|hres_active\|clock\|event_handler' cpu: 0 clock 0: .resolution: 1 nsecs #2: <ffffc9000214ba00>, hrtimer_wakeup, S:01, schedule_hrtimeout_range_clock.part.28, rpcbind/507 #3: <ffffc900026d7d80>, hrtimer_wakeup, S:01, schedule_hrtimeout_range_clock.part.28, cleanupd/585 #4: <ffffc9000269fd80>, hrtimer_wakeup, S:01, schedule_hrtimeout_range_clock.part.28, smbd-notifyd/584 #8: <ffffc9000261fd80>, hrtimer_wakeup, S:01, schedule_hrtimeout_range_clock.part.28, smbd/583 #9: <ffffc9000212bd80>, hrtimer_wakeup, S:01, schedule_hrtimeout_range_clock.part.28, syslog-ng/494 #10: <ffffc900026dfd80>, hrtimer_wakeup, S:01, schedule_hrtimeout_range_clock.part.28, lpqd/587 clock 1: .resolution: 1 nsecs clock 2: .resolution: 1 nsecs clock 3: .resolution: 1 nsecs .get_time: ktime_get_clocktai .hres_active : 1 cpu: 2 clock 0: .resolution: 1 nsecs #2: <ffffc90002313a00>, hrtimer_wakeup, S:01, schedule_hrtimeout_range_clock.part.28, thermald/548 #3: <ffffc900023fb8c0>, hrtimer_wakeup, S:01, schedule_hrtimeout_range_clock.part.28, wpa_supplicant/562 clock 1: .resolution: 1 nsecs clock 2: .resolution: 1 nsecs clock 3: .resolution: 1 nsecs .get_time: ktime_get_clocktai .hres_active : 1 event_handler: tick_handle_oneshot_broadcast event_handler: hrtimer_interrupt event_handler: hrtimer_interrupt
pthread_…() POSIX Linux isochronous scheduling¶
An isochronous application is one which will be repeated after a fixed period of time:
The execution time of this application should always be less than its period.
An isochronous application should always be a real time thread to measure performance.
Below are step-by-step program breakdown to develop simple isoch-rt-thread sanity-check test:
step - Define a structures that will have the time period information along with the current time of the clock. This structure will be used to pass the data between multiple tasks.
/*Data format to be passed between tasks*/ struct time_period_info { struct timespec next_period; long period_ns;
step - Define the time period of the cyclic thread to 1ms and get the current time of the system.
/*Initialize the periodic task with 1ms time period*/ static void initialize_periodic_task(struct time_period_info *tinfo) { /* keep time period for 1ms */ tinfo->period_ns = 1000000; clock_gettime(CLOCK_MONOTONIC, &(tinfo->next_period)); }
step - Use Timer increment module to go for nanosleep to complete the time period of the real-thread.
/*Increment the timer until the time period elapses and the Real time task will execute*/ static void inc_period(struct time_period_info *tinfo) { tinfo->next_period.tv_nsec += tinfo->period_ns; while(tinfo->next_period.tv_nsec >= 1000000000){ tinfo->next_period.tv_sec++; tinfo->next_period.tv_nsec -=1000000000; } }
step - Use a loop for waiting for time period completion. Assumption here is thread execution time is less as compared to time period
/*Assumption: Real time task requires less time to complete task as compared to period length, so wait till period completes*/ static void wait_for_period_complete(struct period_info *pinfo) { inc_period(pinfo); /* Ignore possibilities of signal wakes */ clock_nanosleep(CLOCK_MONOTONIC, TIMER_ABSTIME, &pinfo->next_period, NULL); }
step - Define a Real-Time thread here. For simplicity a print statement is kept here.
static void real_time_task() { printf("Real-Time Task executing\n"); return NULL; }
step - Initialize and trigger the realtime thread cyclic execution. Also will wait for the time period completion. This thread will be created from the main thread as a POSIX thread.
void *realtime_isochronous_task(void *data) { struct time_period_info tpinfo; periodic_task_init(&tpinfo); while (1) { real_time_task(); wait_for_period_complete(&tpinfo); } return NULL; }
Note
A non real time main thread will spawn a Real-time isochronous application thread here. Also it sets the preemptive scheduling priority and policy.
step - created a POSIX main thread to create & initialize all threads with the attributes.
int main(int argc, char* argv[]) { struct sched_param param_fifo; pthread_attr_t attr_fifo; pthread_t thread_fifo; int status = -1; memset(¶m_fifo, 0, sizeof(param_fifo)); status = pthread_attr_init(&attr_fifo); if (status) { printf("pthread_attr_init failed\n"); return status; }
Next, Set the Real time thread with FIFO scheduling policy here.
status = pthread_attr_setschedpolicy(&attr_fifo, SCHED_FIFO); if (status) { printf("pthread_attr_setschedpolicy failed\n"); return status; }
The Real time task priority is kept here as 92. The priority can be choose between 1-99.
param_fifo.sched_priority = 92; status = pthread_attr_setschedparam(&attr_fifo, ¶m_fifo); if (status) { printf("pthread_attr_setschedparam failed\n"); return status; }
Set the inherit-scheduler attribute of the thread attribute. The inherit-scheduler attribute determines if new thread takes scheduling attributes from the calling thread or from the attr.
status = pthread_attr_setinheritsched(&attr_fifo, PTHREAD_EXPLICIT_SCHED); if (status) { printf("pthread_attr_setinheritsched failed\n"); return status; }
Real Time isochronous application thread will be created here.
status = pthread_create(&thread_fifo, &attr_fifo, realtime_isochronous_task, NULL); if (status) { printf("pthread_create failed\n"); return status; }
Wait for Real Time task completion
pthread_join(thread_fifo, NULL); return status; }
Find the complete code example below.
/*Header Files*/ #include <pthread.h> #include <stdio.h> #include <string.h> /*Data format to be passed between tasks*/ struct time_period_info { struct timespec next_period; long period_ns; }; /*Initialize the periodic task with 1ms time period*/ static void initialize_periodic_task(struct time_period_info *tinfo){ /*Keep time period for 1ms*/ tinfo->period_ns = 1000000; clock_gettime(CLOCK_MONOTONIC, &(tinfo->next_period)); } /*Increment the timer to till time period elapsed*/ static void inc_period(struct time_period_info *tinfo){ tinfo->next_period.tv_nsec += tinfo->period_ns; while(tinfo->next_period.tv_nsec >= 1000000000){ tinfo->next_period.tv_sec++; tinfo->next_period.tv_nsec -=1000000000; } } /*Real time task requires less time to complete task as compared to period length, so wait till period completes*/ static void wait_for_period_complete(struct time_period_info *tinfo){ inc_period(tinfo); clock_nanosleep(CLOCK_MONOTONIC, TIMER_ABSTIME, &tinfo->next_period, NULL); } /*Real Time Task*/ static void* real_time_task(){ printf("Real-Time Task executing\n"); return NULL; } /*Main module for an isochronous application task with Real Time priority and scheduling call as SCHED_FIFO */ void *realtime_isochronous_task(void *data){ struct time_period_info tinfo; initialize_periodic_task(&tinfo); while(1){ real_time_task(); wait_for_period_complete(&tinfo); } return NULL; } /*Non Real Time master thread that will spawn a Real Time isochronous application thread*/ int main(int argc, char* argv[]) { struct sched_param param_fifo; pthread_attr_t attr_fifo; pthread_t thread_fifo; int status = -1; memset(¶m_fifo, 0, sizeof(param_fifo)); status = pthread_attr_init(&attr_fifo); if (status) { printf("pthread_attr_init failed\n"); return status; } status = pthread_attr_setschedpolicy(&attr_fifo, SCHED_FIFO); if (status) { printf("pthread_attr_setschedpolicy failed\n"); return status; } param_fifo.sched_priority = 92; status = pthread_attr_setschedparam(&attr_fifo, ¶m_fifo); if (status) { printf("pthread_attr_setschedparam failed\n"); return status; } status = pthread_attr_setinheritsched(&attr_fifo, PTHREAD_EXPLICIT_SCHED); if (status) { printf("pthread_attr_setinheritsched failed\n"); return status; } status = pthread_create(&thread_fifo, &attr_fifo, realtime_isochronous_task, NULL); if (status) { printf("pthread_create failed\n"); return status; } pthread_join(thread_fifo, NULL); return status; }
Setting thread temporal-isolation via kernel boot parameters¶
Assuming the following best known configuration to implement CPU core Temporal-isolation:
cpu2 (Critical Core): will run our real-time applications
cpu0: will run everything else
See the table below for a non-exhaustive list of kernel cmdline options that act upon thread/process cores affinity at boot-time :
cmdline |
Parameter |
Isolation |
|---|---|---|
|
List of critical cores |
The kernel scheduler will not migrate tasks from other cores to them |
|
List of non-critical cores |
Protects the cores from IRQs |
|
List of critical cores |
Stops RCU callbacks from getting called |
|
List of critical cores |
If the core is idle or has a single running task, it will not get scheduling clock ticks. Use together with nohz=off so dynamic ticks do not impact latencies. |
In our case, the resulting parameters will look like:
isolcpus=2 irqaffinity=0 rcu_nocbs=2 nohz=off nohz_full=2
For Editing systemd-bootx64.efi OS loader entry file to add custom boot parameters:
root@intel-corei7-64:~# vi /boot/EFI/loader/entries/boot.conf
title boot
linux /vmlinuz
initrd /initrd
options LABEL=boot isolcpus=2 irqaffinity=0 rcu_nocbs=2 nohz=off nohz_full=2 i915.enable_rc6=0 i915.enable_dc=0 i915.disable_power_well=0 i915.enable_execlists=0 i915.powersave=0 processor.max_cstate=0 intel.max_cstate=0 processor_idle.max_cstate=0 intel_idle.max_cstate=0 clocksource=tsc tsc=reliable nmi_watchdog=0 nosoftlockup intel_pstate=disable noht nosmap mce=ignore_mce nohalt acpi_irq_nobalance noirqbalance vt.handoff=7
Xenomai3/i-pipe Cobalt preemptive & priority scheduling Linux OS runtime¶
The Xenomai project (https://xenomai.org) is an open-source RTOS-to-Linux Portability Framework under Creative Commons BY-SA 3.0 and GPLv2 Licenses which comes in two flavors:
As co-kernel/real-time extension(RTE) for patched Linux codename Cobalt
As libraries for native Linux (incl. PREEMPT-RT) codename Mercury. It aims at working both as a co-kernel and on top of PREEMPT_RT in the 3.0 branch.
Xenomai project merged a real-time core (named Cobalt core) into Linux kernel, which co-exists in kernel space. The interrupts and threads in the Cobalt core have higher priority than the interrupts and threads in Linux kernel. Since the Cobalt core executes with less instructions compared to the Linux kernel, unnecessary delay and historical burden in calling path can be reduced.

Using this real-time targeted design, a Xenomai-patched Linux kernel can achieve quite a good real-time multi-threading performance.
Setting 2-stage interrupt pipeline [Head] and [Root] stages¶
The 2-stage interrupt pipeline is the underlying mechanism enabling the Xenomai real-time framework.
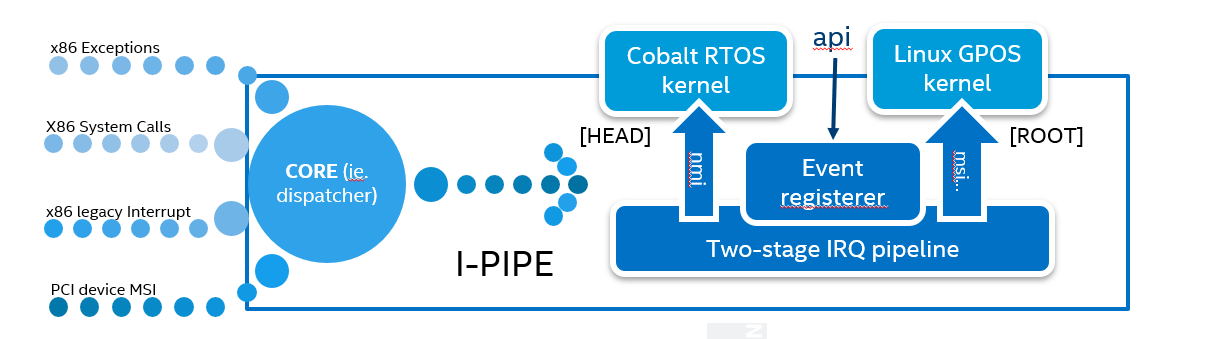
The Xenomai-patched Linux kernel takes dominance over hardware interrupts which originally belong to the Linux kernel. Xenomai will firstly handle the interrupts it is interested in, and then route the other interrupts to the Linux kernel. The former named head stage and the latter is named root stage:
The [Head] stage corresponds to the Cobalt core (real-time domain or out-of-band context)
The root stage corresponds to the Linux kernel (non real-time domain or in-band context)
The head stage has higher priority over the root stage, and offers the shortest response time by squeezing both the hardware and software.
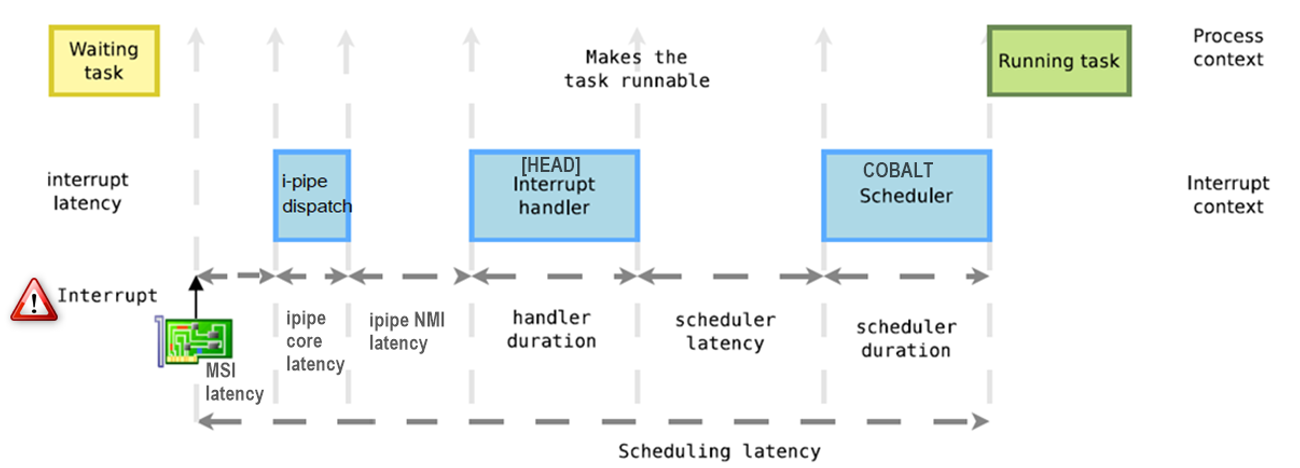
The Xenomai patches that implement these mechanics are named I-pipe patches; the x86 version patches are hosted at: https://xenomai.org/gitlab/ipipe-x86
Setting POSIX thread context migration between [Head] and [Root] stages¶
On Linux, the taskset command allows a user to change a process’s CPU affinity. It is typically used in conjunction with the CPU isolation determined by the kernel cmdline. The example script below demonstrates changing the real-time process affinity to Core 1:
#!/bin/bash
cpu="1"
cycle="250"
time_total="345600"
taskset -c $cpu /usr/bin/latency -g ./latency.histo.log -s -p $cycle -c $cpu -P 99 -T $time_total 2>&1 | tee ./latency.log
Ensuring that workloads are running isolated on CPUs can be determined by monitoring the state of currently running tasks. One such utility that enables monitoring of task CPU affinity is htop.
Cobalt core’s threads are not entirely isolated from the Linux kernel’s threads. Instead, it reuses ordinary kthread and adds special capabilities; kthread can jump between Cobalt’s real-time context (out-of-band context) and common Linux kernel context (in-band context). The advantage is when under in-band context the thread can enjoy Linux kernel’s infrastructure. A typical scenario is a Cobalt thread will start up as a normal kthread, call the Linux kernel’s API for preparation work, then switch to out-of-band context and behave as a Cobalt thread to perform real-time work. The disadvantage is during out-of-band context the Cobalt thread is quite easily migrated to in-band context by a mistakenly called Linux kernel API. In such a case it is quite difficult discover; developers misleadingly consider their thread to be running under the Cobalt core, and don’t notice the issue until checking the ftrace output or when the task exceeds its deadline.
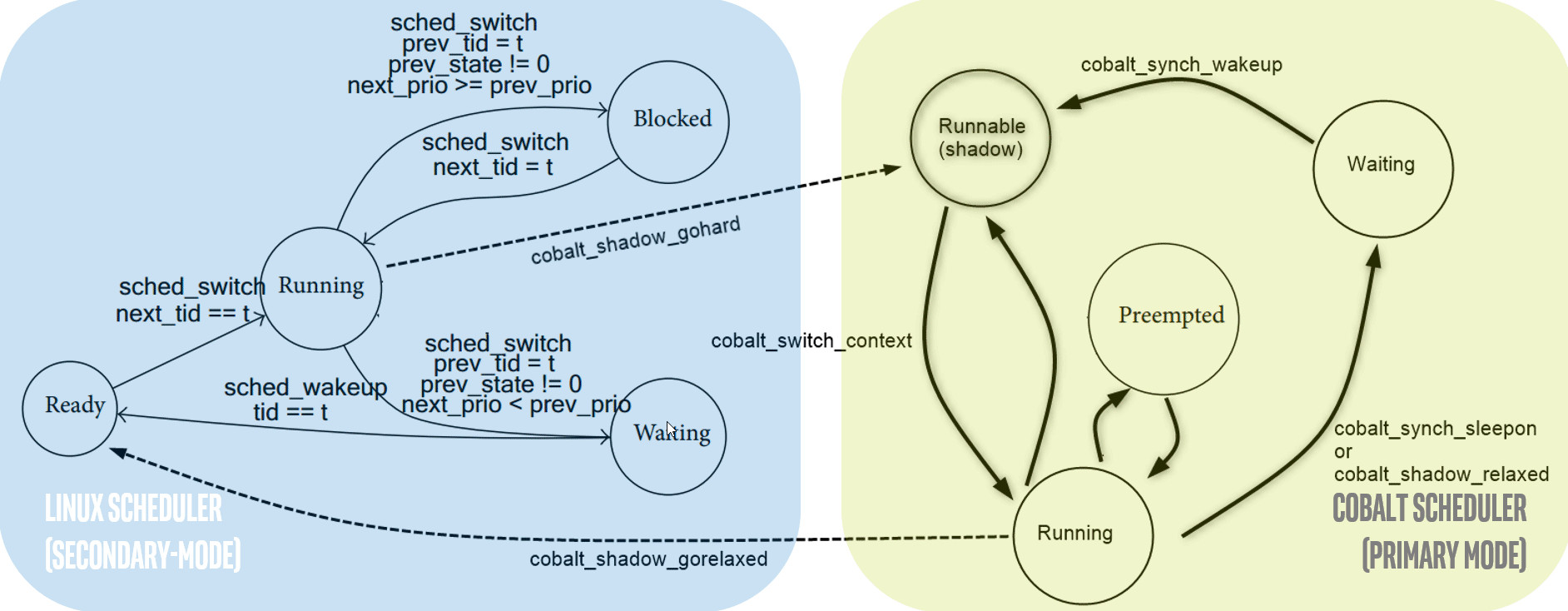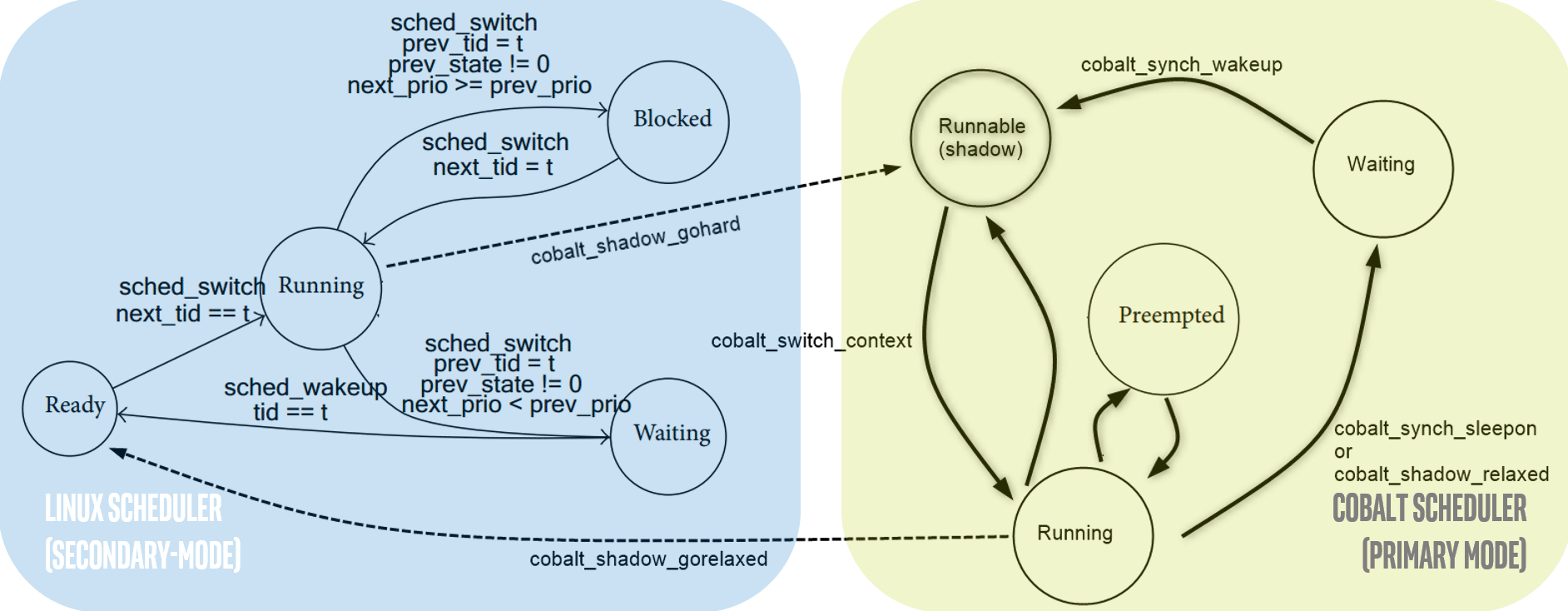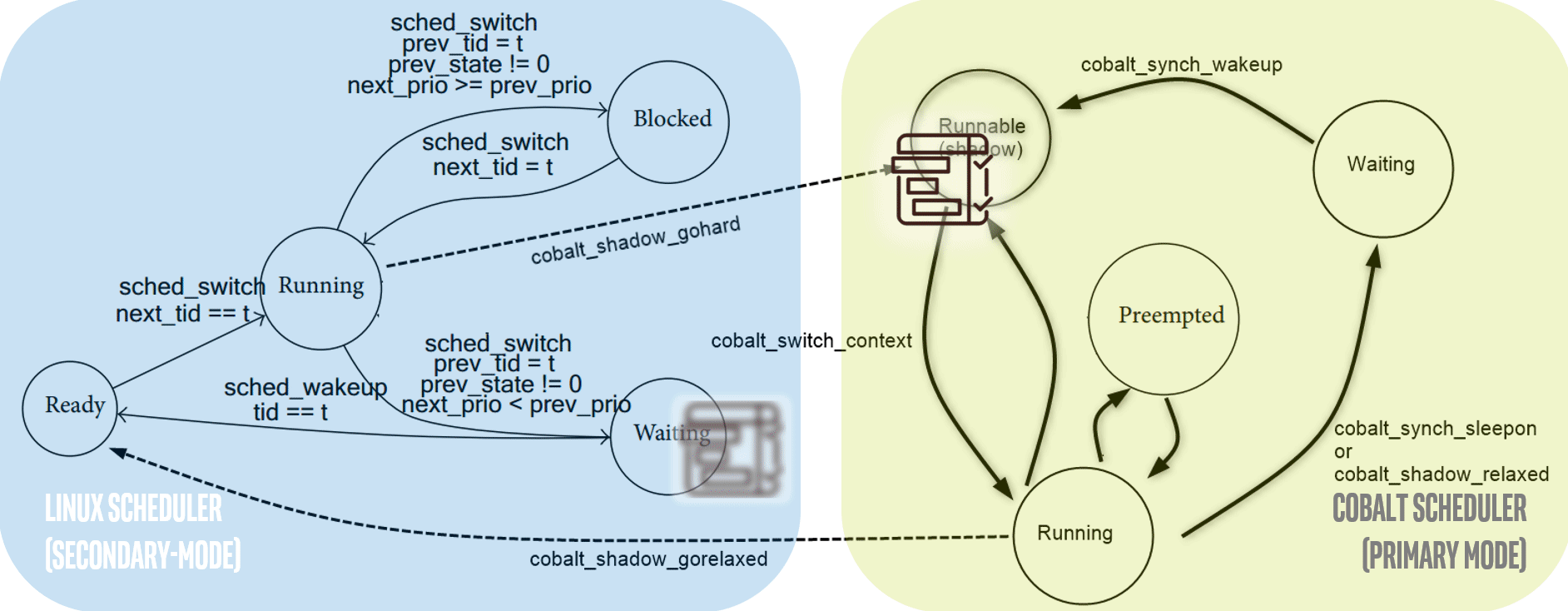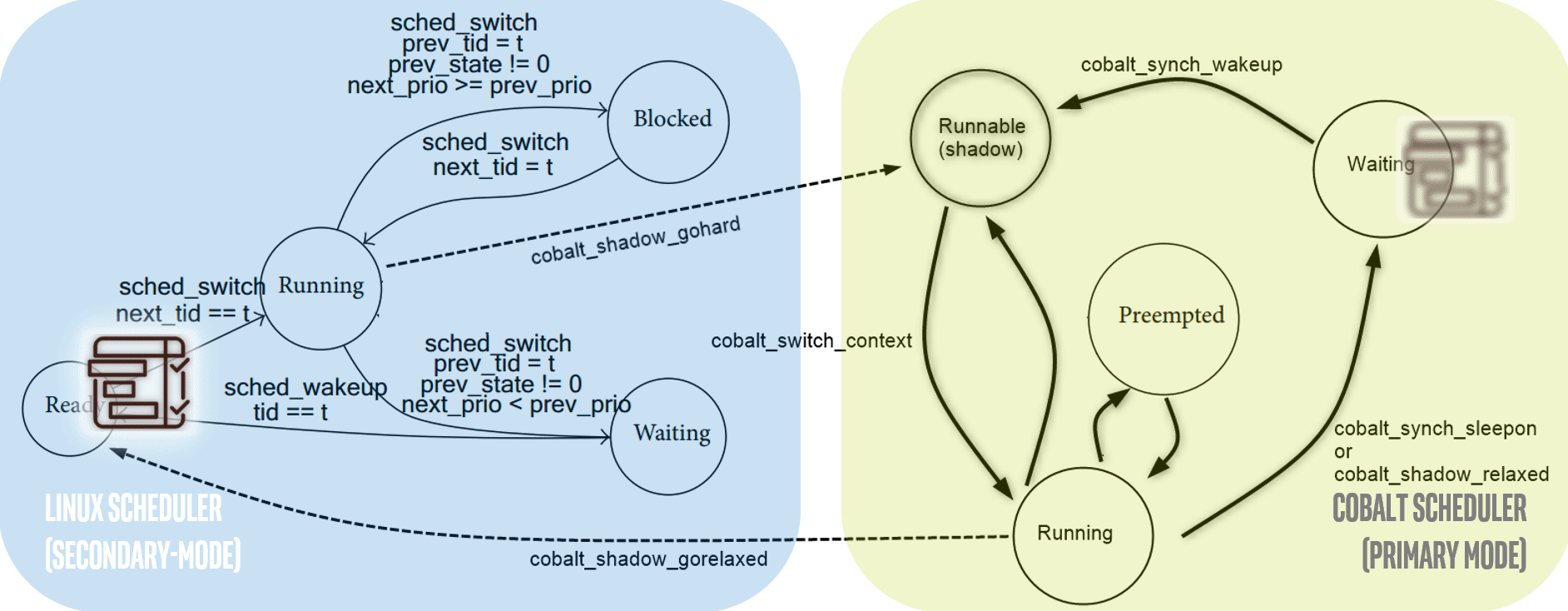
A Xenomai/Cobalt POSIX-based userspace application can shadow the same thread between Preemptive and Common Time-Sharing (SCHED_OTHER) scheduling policy:
Secondary mode: all where Linux GPOS services and Linux [ROOT] domain device drivers are accessible (i.e.
ps –xortopLinux commands can be used).Primary mode: all where all Xenomai RTOS services and RTDM [HEAD] domain device drivers are accessible
# root@intel-corei7-64:~# cat /proc/xenomai/sched/stat
CPU PID MSW CSW XSC PF STAT %CPU NAME
0 0 0 5321688352 0 0 00018000 96.8 [ROOT/0]
1 0 0 1067292 0 0 00018000 100.0 [ROOT/1]
1 852 1 1 5 0 000680c0 0.0 latency
1 854 532167 1064334 532171 0 00068042 0.0 display-852
0 855 2 5321669632 5322202288 0 0004c042 2.4 sampling-852
1 0 0 13288313 0 0 00000000 0.0 [IRQ4355: [timer]]
pthread POSIX skin runtime scheduling APIs¶
When linked with libcobalt.so, Linux pthread_create() with pthread_setschedparam() policy SCHED_FIFO and SCHED_RR POSIX scheduling system calls are trampolined to Xenomai/Cobalt task by a mechanism called shadowing.
On top of those Xenomai/cobalt provide also specific scheduling policies :
SCHED_TPimplements the temporal partitioning scheduling policy for groups of threads (a group can be one or more threads)SCHED_SPORADICimplements a task server scheduler used to run sporadic activities with quota to avoid periodic (under SCHED_RR or SCHED_FIFO) tasks perturbationSCHED_QUOTAimplements a budget-based scheduling policy. The group of threads is suspended since the budget exceeded. The budget is refilled every quota interval
Setting High Resolution Timers thread in Xenomai¶
Xenomai3/Cobalt High Resolution Timers (CONFIG_XENO_OPT_TIMER_RBTREE=y) allows to use the available X86 hardware timers to create time-interval based of high-priority [HEAD] interrupts:
[host-timer/x]and[watchdog]multiplexed into number of software programmable timers exposed to the Cobalttimerfd_handlerPOSIX timers API call from userspaceclock_nanosleep()thread accurate wakeup by high-resolution timer hw-offload.
Linux Userspace filesystem interface allow user to report cobalt timer information:
# cat /proc/xenomai/timer/coreclk
CPU SCHED/SHOT TIMEOUT INTERVAL NAME
0 79845094/32427139 419us - [host-timer/0]
0 673759/673758 164ms579us 1s [watchdog]
1 41484498/15201506 419us - [host-timer/1]
1 673759/673758 164ms583us 1s [watchdog]
0 2440455925/2440400928 94us 100us timerfd_handler
Further reading reference¶
This document will not cover all the technical details of the Xenomai framework. Please refer to the official documentation for further reading.
ipipe (kernel documentation)
https://xenomai.org/documentation/xenomai-3/html/xeno3prm/index.html
RT-Scheduling Sanity-Check Testing¶
The following section is applicable to:

The following test procedure admin user logs in as root user.
Sanity-Check #1: User Monitor Thread CPU core Affinity¶
Step - run ps command to report tree of all the processes executing on the computer, listed together with their Process ID, Scheduling Policy, Real-Time Priority and Command Line by running:
root@intel-corei7-64:~# ps f -g 0 -o pid,policy,rtprio,cmd PID POL RTPRIO CMD 2 TS - [kthreadd] 3 TS - \_ [ksoftirqd/0] 4 FF 1 \_ [ktimersoftd/0] 6 TS - \_ [kworker/0:0H] 8 FF 1 \_ [rcu_preempt] 9 FF 1 \_ [rcu_sched] 10 FF 1 \_ [rcub/0] 11 FF 1 \_ [rcuc/0] 12 TS - \_ [kswork] 13 FF 99 \_ [posixcputmr/0] 14 FF 99 \_ [migration/0] 15 TS - \_ [cpuhp/0] 16 TS - \_ [cpuhp/2] 17 FF 99 \_ [migration/2] 18 FF 1 \_ [rcuc/2] 19 FF 1 \_ [ktimersoftd/2] 20 TS - \_ [ksoftirqd/2] 22 TS - \_ [kworker/2:0H] 23 FF 99 \_ [posixcputmr/2] 24 TS - \_ [kdevtmpfs] 25 TS - \_ [netns] 27 TS - \_ [oom_reaper] 28 TS - \_ [writeback] 29 TS - \_ [kcompactd0] 30 TS - \_ [crypto] 31 TS - \_ [bioset] 32 TS - \_ [kblockd] 33 FF 50 \_ [irq/9-acpi] 34 TS - \_ [md] 35 TS - \_ [watchdogd] 36 TS - \_ [rpciod] 37 TS - \_ [xprtiod] 39 TS - \_ [kswapd0] 40 TS - \_ [vmstat] 41 TS - \_ [nfsiod] 63 TS - \_ [kthrotld] 66 TS - \_ [bioset] 67 TS - \_ [bioset] 68 TS - \_ [bioset] 69 TS - \_ [bioset] 70 TS - \_ [bioset] 71 TS - \_ [bioset] 72 TS - \_ [bioset] 73 TS - \_ [bioset] 74 TS - \_ [bioset] 75 TS - \_ [bioset] 76 TS - \_ [bioset] 77 TS - \_ [bioset] 78 TS - \_ [bioset] 79 TS - \_ [bioset] 80 TS - \_ [bioset] 81 TS - \_ [bioset] 83 TS - \_ [bioset] 84 TS - \_ [bioset] 85 TS - \_ [bioset] 86 TS - \_ [bioset] 87 TS - \_ [bioset] 88 TS - \_ [bioset] 89 TS - \_ [bioset] 90 TS - \_ [bioset] 92 FF 50 \_ [irq/27-idma64.0] 93 FF 50 \_ [irq/27-i2c_desi] 94 FF 50 \_ [irq/28-idma64.1] 95 FF 50 \_ [irq/28-i2c_desi] 96 FF 50 \_ [irq/29-idma64.2] 98 FF 50 \_ [irq/29-i2c_desi] 100 FF 50 \_ [irq/30-idma64.3] 101 FF 50 \_ [irq/30-i2c_desi] 102 FF 50 \_ [irq/31-idma64.4] 103 FF 50 \_ [irq/31-i2c_desi] 104 FF 50 \_ [irq/32-idma64.5] 106 FF 50 \_ [irq/32-i2c_desi] 107 FF 50 \_ [irq/33-idma64.6] 108 FF 50 \_ [irq/33-i2c_desi] 109 FF 50 \_ [irq/34-idma64.7] 110 FF 50 \_ [irq/34-i2c_desi] 111 FF 50 \_ [irq/4-idma64.8] 112 FF 50 \_ [irq/5-idma64.9] 113 FF 50 \_ [irq/35-idma64.1] 115 FF 50 \_ [irq/37-idma64.1] 117 TS - \_ [nvme] 118 FF 50 \_ [irq/365-xhci_hc] 121 TS - \_ [scsi_eh_0] 122 TS - \_ [scsi_tmf_0] 123 TS - \_ [usb-storage] 124 TS - \_ [dm_bufio_cache] 125 FF 50 \_ [irq/39-mmc0] 126 FF 49 \_ [irq/39-s-mmc0] 127 FF 50 \_ [irq/42-mmc1] 128 FF 49 \_ [irq/42-s-mmc1] 129 TS - \_ [ipv6_addrconf] 144 TS - \_ [bioset] 175 TS - \_ [bioset] 177 TS - \_ [mmcqd/0] 182 TS - \_ [bioset] 187 TS - \_ [mmcqd/0boot0] 189 TS - \_ [bioset] 191 TS - \_ [mmcqd/0boot1] 193 TS - \_ [bioset] 195 TS - \_ [mmcqd/0rpmb] 332 TS - \_ [kworker/2:1H] 342 TS - \_ [kworker/0:1H] 407 TS - \_ [jbd2/mmcblk0p2-] 409 TS - \_ [ext4-rsv-conver] 429 TS - \_ [bioset] 463 TS - \_ [loop0] 466 TS - \_ [jbd2/loop0-8] 467 TS - \_ [ext4-rsv-conver] 558 FF 50 \_ [irq/366-mei_me] 559 FF 50 \_ [irq/8-rtc0] 560 FF 50 \_ [irq/35-pxa2xx-s] 561 TS - \_ [spi1] 563 FF 50 \_ [irq/37-pxa2xx-s] 564 TS - \_ [spi3] 572 FF 50 \_ [irq/369-i915] 798 FF 1 \_ [i915/signal:0] 800 FF 1 \_ [i915/signal:1] 801 FF 1 \_ [i915/signal:2] 802 FF 1 \_ [i915/signal:4] 832 FF 50 \_ [irq/367-enp2s0] 835 FF 50 \_ [irq/368-enp3s0] 844 FF 50 \_ [irq/4-serial] 846 FF 50 \_ [irq/5-serial] 4167 TS - \_ [kworker/0:1] 4194 TS - \_ [kworker/u8:1] 4234 TS - \_ [kworker/2:0] 4242 TS - \_ [kworker/0:0] 4288 TS - \_ [kworker/u8:0] 4313 TS - \_ [kworker/2:1] 4318 TS - \_ [kworker/0:2] 1 TS - /sbin/init initrd=\initrd LABEL=boot processor.max_cstate=0 intel_idle.max_cstate=0 clocksource=tsc tsc=reliable nmi_watchdog=0 nosoftlockup intel_pstate=disable i915.disable_power_well=0 i915.enable_rc6=0 noht 3 snd_hda_intel.power_save=1 snd_hda_intel.power_save_controller=y scsi_mod.scan=async console=ttyS2,115200 rootwait console=ttyS0,115200 console=tty0 491 TS - /lib/systemd/systemd-journald 525 TS - /lib/systemd/systemd-udevd 551 TS - /usr/sbin/syslog-ng -F -p /var/run/syslogd.pid 571 TS - /usr/sbin/jhid -d 625 TS - /usr/sbin/connmand -n 629 TS - /lib/systemd/systemd-logind 631 TS - /usr/sbin/thermald --no-daemon --dbus-enable 658 TS - /usr/sbin/ofonod -n 712 TS - /usr/sbin/acpid 828 TS - /sbin/agetty --noclear tty1 linux 829 TS - /sbin/agetty -8 -L ttyS0 115200 xterm 830 TS - /sbin/agetty -8 -L ttyS1 115200 xterm 834 TS - /usr/sbin/wpa_supplicant -u 836 TS - /usr/sbin/nmbd 849 TS - /usr/sbin/smbd 850 TS - \_ /usr/sbin/smbd 851 TS - \_ /usr/sbin/smbd 853 TS - \_ /usr/sbin/smbd 855 TS - /usr/sbin/dropbear -i -r /etc/dropbear/dropbear_rsa_host_key -B 856 TS - \_ -sh 3804 TS - /usr/sbin/dropbear -i -r /etc/dropbear/dropbear_rsa_host_key -B 3805 TS - \_ -sh 4394 TS - \_ ps f -g 0 -o pid,policy,rtprio,cmd 4393 TS - /sbin/agetty -8 -L ttyS2 115200 xterm
Expected outcomes :
The processes between brackets belong to the kernel.
processes with regular Best-Effort CBS scheduling policy (timesharing,
`TS`)processes with a real time policy (FIFO,
`FF`…. )
Step - run
htopis an interactive system-monitor process-viewer and process-manager with the following command:$ htopExpected outcomes:
reports shows a lively updated listing of the processes running on a computer normally ordered by the amount of CPU usage.
Color-coding provides visual information about processor, swap and memory status.
Additional columns can be added to the output of
htop. To configurehtopto filter tasks by CPU affinity, follow the steps below:Press the F2 key to open the menu system
Press the ↓ down arrow key until “Columns” is selected from the “Setup” category
Press the → right arrow key to until the selector moves to the “Available Columns” section
Press the ↓ down arrow key until “PROCESSOR” is selected from the “Available Columns” section
Press the Enter key to add “PROCESSOR” to the “Active Columns” section
Press the F10 key to complete the addition
Press the F6 key to open the “Sort by” menu
Use the ← →↑↓ arrow keys to move the selection to “PROCESSOR”
Press the Enter key to filter tasks by processor affinity
Note
Workloads may consist of many individual child tasks. These child tasks are constituent to the workload and it is acceptable and preferred that they run on the same CPU.
Sanity-Check #2: User Monitor Kernel Interrupts¶
Step - list unwanted interrupts source by monitoring the number of interrupts that occur on a CPU with the following command :
$ watch -n 0.1 cat /proc/interrupts
Expected outcome This command polls the processor every 100 milliseconds and displays interrupt counts. Ideally, isolated CPUs 1, 2, and 3 should not show any interrupt counts incrementing. In practice, the Linux “Local timer interrupt” may still be occurring, but properly prioritized workloads should not be impacted.
Sanity-Check #3: Determine CPU LLC Cache Allocation preset¶
Note
If target system’s CPU supports CAT, it can greatly help to reduce the worst case jitter. Please see section Cache Allocation Technology for description and usage.
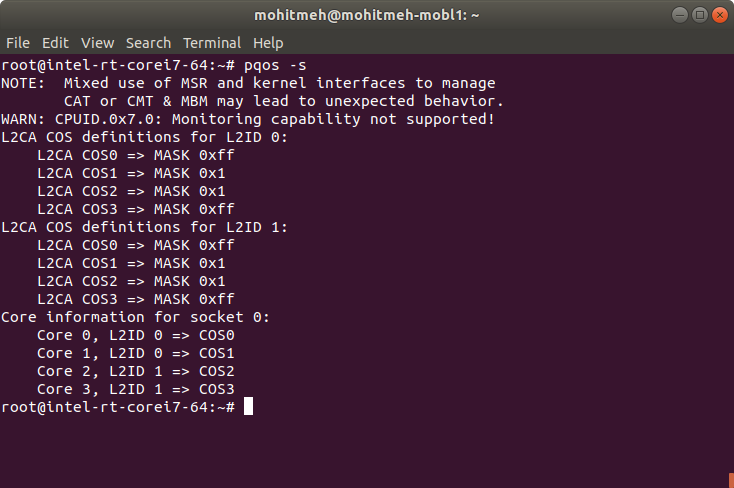
Step - Admin User verify command that cache partitioning configuration per-cpu or per-cpumodules to mitigate LLC cache misses resulting in thread execution overhead , page-fault scheduling penalties,…
$ pqos -s
Expected outcome output from a target system utilizing CAT is shown below:
Sanity-Check #4: Check IA UEFI firmware setting¶
UEFI firmware BIOS menu settings should be modified to improve target system’s real-time performance.
Step - Admin User verify CPU’s speedstep/speedshift Turned-off , CPU frequency fixed CPU always running is stuck C0 state;
Expected outcome please refer to Recommended ECI-B/X BIOS Optimizations
Step - Admin User verify hyper-threading Disable ;
Expected outcome please refer to Recommended ECI-B/X BIOS Optimizations
Step - Admin User verify North-complex power-management policy on Gfx state/frequency and Bus Fabric (ex: Gersville/GV,…);
Expected outcome please refer to Recommended ECI-B/X BIOS Optimizations
Step - Check North-complex IP : PCIe ASPM, USB PM, … (varies greatly by OEM and SKUs).
Expected outcome please refer to power-management policy Recommended ECI-B/X BIOS Optimizations
And remember, the Linux kernel is able to override BIOS’s settings if related hardware register exposed to kernel space.
Note
But BIOS menu show items vary among different board vendors. Some useful config items maybe hidden by OEM and you never have a chance to modify it
Sanity-Check #5: Check Linux kernel cmdline parameters¶
Certain kernel boot parameters should be added for tuning the real-time performance.
Step - Admin User reviews kernel commandline boot to fixed as documented under ECI Kernel Boot Optimizations which isolate CPUs 1,2,3 respectively.
i915.power management Turn on/offprocessor*.andintel*.Power saving and Clocking gating featuresisolcpusCPU isolationirqaffinityCPU interrupt affinity
expected outcomes on example with CPU 1 isolated (reserve for real-time process) and binding irq affinity to CPU 0
i915.enable_rc6=0 i915.enable_dc=0 i915.disable_power_well=0 i915.enable_execlists=0 i915.powersave=0 processor.max_cstate=0 intel.max_cstate=0 processor_idle.max_cstate=0 intel_idle.max_cstate=0 clocksource=tsc tsc=reliable nmi_watchdog=0 nosoftlockup intel_pstate=disable noht nosmap mce=ignore_mce nohalt acpi_irq_nobalance noirqbalance vt.handoff=7 rcu_nocbs=1 rcu_nocb_poll nohz_full=1 isolcpus=1 irqaffinity=0 vt.handoff=1Step - Admin User using
/etc/default/grub, add kernel cmdline toGRUB_CMDLINE_LINUX="", do not forget to runupdate-grubbefore reboot.
Note
Thermal condition of target system must be monitored after changing the BIOS and kernel cmdline. Lower the CPU frequency and use cooling apparatus if the CPU is too hot.
Sanity-Check #6: User reports thread KPIs as latency histograms¶
The minimally invasive Linux tracing events are commonly used to report latency histogram of a particular thread over long runtime. For example
Thread wakeup + scheduling + execution time KPIs overhead
Thread semaphore acquire/release performance
Thread WCET jitter
…
Step - Admin User checks if kernel CONFIG enables
/sys/kernel/debug/tracingto established comparable KPIs measurement across various Linux kernel runtimes ie. PREEMPT_RT and COBALTif [ -d /sys/kernel/debug/tracing ] ; then echo PASS; else echo FAIL; fiexpected outcomes PASS
Step - Admin User checks trace-event ram-buffer records multi-threaded scheduling timeline time precision (ie. nanosecond TSC-clock epoch-time) .
echo nop > /sys/kernel/debug/tracing/tracer echo 1 > /sys/kernel/debug/tracing/events/sched/sched_wakeup/enable echo 1 > /sys/kernel/debug/tracing/events/sched/sched_switch/enable echo 1 > /sys/kernel/debug/tracing/trace_on sleep 5 echo 0 > /sys/kernel/debug/tracing/trace_on echo 0 > /sys/kernel/debug/tracing/events/sched/sched_wakeup/enable echo 0 > /sys/kernel/debug/tracing/events/sched/sched_switch/enable
Exporting all records into filesystem
cat /sys/kernel/debug/tracing/trace > ~/ftrace_buffer_dump.txtexpected outcomes
Task2-1891 ( 1026) [000] d..h2.. 6528.499461: hrtimer_cancel: hrtimer=ffffb09ec138be58 Task2-1891 ( 1026) [000] d..h1.. 6528.499461: hrtimer_expire_entry: hrtimer=ffffb09ec138be58 function=hrtimer_wakeup now=6528499005755 ts0--> Task2-1891 ( 1026) [000] d..h2.. 6528.499461: sched_waking: comm=Task pid=1890 prio=33 target_cpu=000 Task2-1891 ( 1026) [000] d..h3.. 6528.499462: sched_wakeup: comm=Task pid=1890 prio=33 target_cpu=000 Task2-1891 ( 1026) [000] d..h1.. 6528.499462: hrtimer_expire_exit: hrtimer=ffffb09ec138be58 Task2-1891 ( 1026) [000] d..h1.. 6528.499462: write_msr: 6e0, value 136d628c2e73e7 Task2-1891 ( 1026) [000] d..h1.. 6528.499463: local_timer_exit: vector=239 Task2-1891 ( 1026) [000] d...2.. 6528.499463: sched_waking: comm=ktimersoftd/0 pid=8 prio=98 target_cpu=000 Task2-1891 ( 1026) [000] d...3.. 6528.499463: sched_wakeup: comm=ktimersoftd/0 pid=8 prio=98 target_cpu=000 Task2-1891 ( 1026) [000] ....... 6528.499464: sys_exit: NR 202 = 1 Task2-1891 ( 1026) [000] ....1.. 6528.499464: sys_futex -> 0x1 Task2-1891 ( 1026) [000] ....... 6528.499472: sys_enter: NR 230 (1, 1, 7ff75266fdb0, 0, 2, 7fff10bda080) Task2-1891 ( 1026) [000] ....1.. 6528.499472: sys_clock_nanosleep(which_clock: 1, flags: 1, rqtp: 7ff75266fdb0, rmtp: 0) Task2-1891 ( 1026) [000] ....... 6528.499472: hrtimer_init: hrtimer=ffffb09ec13bbe58 clockid=CLOCK_MONOTONIC mode=ABS Task2-1891 ( 1026) [000] d...1.. 6528.499473: hrtimer_start: hrtimer=ffffb09ec13bbe58 function=hrtimer_wakeup expires=6528499988112 softexpires=6528499988112 mode=ABS Task2-1891 ( 1026) [000] d...1.. 6528.499473: write_msr: 6e0, value 136d628c2e1be1 Task2-1891 ( 1026) [000] d...1.. 6528.499474: rcu_utilization: Start context switch Task2-1891 ( 1026) [000] d...1.. 6528.499474: rcu_utilization: End context switch Task2-1891 ( 1026) [000] d...2.. 6528.499475: sched_switch: prev_comm=Task2 prev_pid=1891 prev_prio=33 prev_state=D ==> next_comm=Task next_pid=1890 next_prio=33 Task2-1891 ( 1026) [000] d...2.. 6528.499475: x86_fpu_regs_deactivated: x86/fpu: ffff96a6199156c0 initialized: 1 xfeatures: 3 xcomp_bv: 800000000000001f Task2-1891 ( 1026) [000] d...2.. 6528.499475: write_msr: c0000100, value 7ff75292c700 Task2-1891 ( 1026) [000] d...2.. 6528.499476: x86_fpu_regs_activated: x86/fpu: ffff96a619913880 initialized: 1 xfeatures: 3 xcomp_bv: 800000000000001f Task-1890 ( 1026) [000] ....... 6528.499476: sys_exit: NR 230 = 0 Task-1890 ( 1026) [000] ....1.. 6528.499476: sys_clock_nanosleep -> 0x0 Task-1890 ( 1026) [000] ....... 6528.499482: sys_enter: NR 230 (1, 1, 7ff75292bdb0, 0, 2, 7fff10bda080) Task-1890 ( 1026) [000] ....1.. 6528.499483: sys_clock_nanosleep(which_clock: 1, flags: 1, rqtp: 7ff75292bdb0, rmtp: 0) Task-1890 ( 1026) [000] ....... 6528.499483: hrtimer_init: hrtimer=ffffb09ec138be58 clockid=CLOCK_MONOTONIC mode=ABS Task-1890 ( 1026) [000] d...1.. 6528.499483: hrtimer_start: hrtimer=ffffb09ec138be58 function=hrtimer_wakeup expires=6528500005368 softexpires=6528500005368 mode=ABS Task-1890 ( 1026) [000] d...1.. 6528.499483: rcu_utilization: Start context switch Task-1890 ( 1026) [000] d...1.. 6528.499484: rcu_utilization: End context switch ts1--> Task-1890 ( 1026) [000] d...2.. 6528.499484: sched_switch: prev_comm=Task prev_pid=1890 prev_prio=33 prev_state=D ==> next_comm=rcuc/0 next_pid=12 next_prio=98
Step - Admin User reviews trace-event specific print format
cat /sys/kernel/debug/tracing/events/cobalt_core/sched_switch/format cat /sys/kernel/debug/tracing/events/cobalt_core/cobalt_switch_context/format
expected outcomes
name: cobalt_switch_context ID: 451 format: field:unsigned short common_type; offset:0; size:2; signed:0; field:unsigned char common_flags; offset:2; size:1; signed:0; field:unsigned char common_preempt_count; offset:3; size:1; signed:0; field:int common_pid; offset:4; size:4; signed:1; field:struct xnthread * prev; offset:8; size:8; signed:0; field:struct xnthread * next; offset:16; size:8; signed:0; field:__data_loc char[] prev_name; offset:24; size:4; signed:1; field:__data_loc char[] next_name; offset:28; size:4; signed:1; print fmt: "prev=%p(%s) next=%p(%s)", REC->prev, __get_str(prev_name), REC->next, __get_str(next_name)
Step - Admin User enables a primary trace-event as
hist:keys triggerstart conditionhist:keys trigger= Add event data to a histogram instead of logging it to the trace bufferif ()event filters narrow down number of events triggers.vals=variables evaluate and Save multi-event quantities
$ echo 'hist:keys=common_pid:vals=$ts0,$root:ts0=common_timestamp.usecs if ( comm == "IEC_mainTask" )' >> \ /sys/kernel/debug/tracing/events/sched/sched_wakeup/trigger
expected outcomes
$ cat /sys/kernel/debug/tracing/events/sched/sched_wakeup/hist # event histogram # # trigger info: hist:keys=common_pid:vals=hitcount,common_timestamp.usecs,pid:ts0=common_timestamp.usecs:sort=hitcount:size=2048:clock=global if ( name == "Task-1890" ) [active] # { common_pid: 1890 } hitcount: 146 common_timestamp: 8563360302 Totals: Hits: 146 Entries: 1 Dropped: 0
Step - Admin User enables
synthetic_eventsas mean to create user-defined trace-events.$ echo 'iectask_wcet u64 lat; ; pid_t pid;' > \ /sys/kernel/debug/tracing/synthetic_events $ cat /sys/kernel/debug/tracing/synthetic_events/iectask_wcet/format
expected outcomes N/A
Step - Admin User enables a secondary trace events
hist:keys triggerstop condition and actions.Trigger actions inject quantities seamlessly back into the trace event subsystem
onmatch().xxxx= generate synthetic eventsonmax()= save() maximum latency values and arbitrary contextsnapshot()= generate any a small porting of ftrace buffer
$ echo 'hist:keys=common_pid:latency=common_timestamp.usecs-$ts0:\ onmatch(sched.sched_switch).iectask_wcet($latency,pid) \ if ( prev_comm == "IEC_mainTask" )' >> \ /sys/kernel/debug/tracing/events/sched/sched_switch/trigger
expected outcomes N/A
Step - Admin User report
synthetic_eventsas an histograms sorted from Min-to-Max.$ echo 'hist:keys=pid,lat:sort=pid,lat' \ >> /sys/kernel/debug/tracing/events/synthetic_events/iectask_wcet/trigger $ cat /sys/kernel/debug/tracing/events/synthetic_events/iectask_wcet/hist
expected outcomes N/A
# event histogram # # trigger info: hist:keys=pid,lat:vals=hitcount:sort=pid,lat:size=2048 [active] # { pid: 854, lat: 6 } hitcount: 2 { pid: 854, lat: 7 } hitcount: 109 { pid: 854, lat: 8 } hitcount: 55 { pid: 854, lat: 9 } hitcount: 6 { pid: 854, lat: 10 } hitcount: 2 Totals: Hits: 174 Entries: 5
Note
Some tips and tricks
<event>/triggerSyntax ERROR are reported under <event>/hist (ex. ERROR: Variable already defined: ts2)Systematically ERASE each
<event>/triggerusing the ‘!’ Character BEFORE issuing another command into same <event>/trigger ex. echo ‘!hist:keys=thread:…’ >> <event>/triggerONLY one hist trigger per <event> can exist simultaneously